|
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104 |
- # CNVkit
-
- > Author: Yaqing Liu
- >
- > E-mail: yaqing.liu@outlook.com
- >
-
- CNVkit is a Python library and command-line software toolkit to infer and visualize copy number from high-throughput DNA sequencing data. It is designed for use with hybrid capture, including both whole-exome and custom target panels, and short-read sequencing platforms such as Illumina and Ion Torrent.
-
- Official document: https://cnvkit.readthedocs.io/en/stable/index.html
- ## Install
-
- ```
- # activate choppy environment
- open-choppy-env
- # install app
- choppy install YaqingLiu/CNVkit
- ```
-
- ## Copy number calling pipeline
- 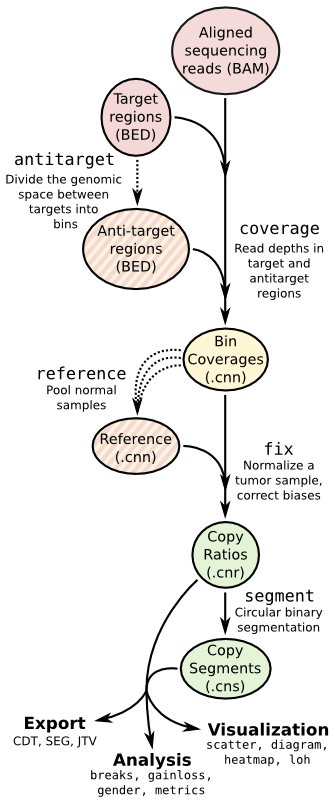
- ## Input
- ```json
- {
- "tumor_bam": [
- "oss://choppy-cromwell-result/...bam",
- "oss://choppy-cromwell-result/...bam",
- "oss://choppy-cromwell-result/...bam"
- ],
- "tumor_bai": [
- "oss://choppy-cromwell-result/...bai",
- "oss://choppy-cromwell-result/...bai",
- "oss://choppy-cromwell-result/...bai"
- ],
- "normal_bam": [
- "oss://choppy-cromwell-result/...bam",
- "oss://choppy-cromwell-result/...bam",
- "oss://choppy-cromwell-result/...bam"
- ],
- "normal_bai": [
- "oss://choppy-cromwell-result/...bai",
- "oss://choppy-cromwell-result/...bai",
- "oss://choppy-cromwell-result/...bai"
- ],
- "sample_id": "...",
- "method": "...",
- "reference": "..." # this parameter is optional
- }
- ```
- ## Note
- <font color=darkred>***-m {hybrid,amplicon,wgs}, --seq-method {hybrid,amplicon,wgs}, --method {hybrid,amplicon,wgs}***</font>
-
- Sequencing assay type: hybridization capture ('hybrid'), targeted amplicon sequencing ('amplicon'), or whole genome sequencing ('wgs').
- Determines whether and how to use antitarget bins.
-
- <font color=darkred>***sequencing-accessible regions***</font>
-
- Many fully sequenced genomes, including the human genome, contain large regions of DNA that are inaccessable to sequencing. (These are mainly the centromeres, telomeres, and highly repetitive regions.) In the FASTA genome sequence these regions are filled in with large stretches of N characters. These regions cannot be mapped by resequencing, so we can avoid them when calculating the antitarget locations by passing the locations of the accessible sequence regions with the -g or --access option.
-
- To use CNVkit on **amplicon sequencing data** instead of hybrid capture – **although this is not recommended** – you can exclude all off-target regions from the analysis by passing the target BED file as the “access” file as well:
-
- ```shell
- cnvkit.py batch ... -t Tiled.bed -g Tiled.bed ...
- ```
-
- This results in empty ”.antitarget.cnn” files which CNVkit will handle safely from version 0.3.4 onward. **However, this approach does not collect any copy number information between targeted regions, so it should only be used if you have in fact prepared your samples with a targeted amplicon sequencing protocol.**
-
-
- ***To reuse an existing reference or create a new:***
-
- *-r REFERENCE, --reference REFERENCE*
-
- Copy number reference file (.cnn).
-
- *--output-reference FILENAME*
-
- Output filename/path for the new reference file being created. (If given, ignores the -o/--output-dir option and will write the file to the given path. Otherwise, "reference.cnn" will be created in the current directory or specified output directory.)
-
- ***--annotate***
-
- The gene annotations file (refFlat.txt) is useful to apply gene names to your baits BED file, if the BED file does not already have short, informative names for each bait interval. This file can be used in the next step.
- If the BED looks like this:
- > chr1 1508981 1509154 SSU72
- >
- > chr1 2407978 2408183 PLCH2
- >
- > chr1 2409866 2410095 PLCH2
-
- Then you don’t need refFlat.txt.
-
- ***index files***
-
- If you’ve prebuilt the index file (.bai, .fai), make sure its timestamp is later than the BAM file’s and fa's.
-
- CNVkit will automatically index the file if needed – that is, if the .bai/.fa file is missing, or if the timestamp of the .bai/.fa file is older than that of the corresponding .bam/.fa file.
-
- ***-s min_gap_size***
-
- Minimum gap size between accessible sequence regions. Regions separated by less than this distance will be joined together. [Default: 5000]
- ## Output
- 1. *.cnn/cns of each sample.
- 2. A whole-genome copy ratio profile as a PDF scatter plot.
- 3. An ideogram of copy ratios on chromosomes as a PDF.
- 4. A segment file which can be imported into IGV.
|

