
 LUYAO REN
5 年前
LUYAO REN
5 年前
共有 13 个文件被更改,包括 2 次插入 和 217 次删除
+ 0
- 0
README.md
查看文件
+ 1
- 3
inputSamplesFileExamples.tsv
查看文件
| @@ -1,3 +1 @@ | |||
| #read1 #read2 #bam #bai #vcf #sample_mark #sample_name #_aln.metrics.txt #_dedup_metrics.txt #_is_metrics.txt #_deduped_coverage_metrics.sample_summary | |||
| oss://chinese-quartet/quartet-test-data/fastqfiles/Fudan_DNA_LCL5_R1.fastq.gz oss://chinese-quartet/quartet-test-data/fastqfiles/Fudan_DNA_LCL5_R2.fastq.gz oss://choppy-cromwell-result/test-choppy/wgs_quartettest_renluyao_0827/7a72d0e6-302d-43ca-b6b0-daeaa0236d06/call-Dedup/Fudan_DNA_LCL5.sorted.deduped.bam oss://choppy-cromwell-result/test-choppy/wgs_quartettest_renluyao_0827/7a72d0e6-302d-43ca-b6b0-daeaa0236d06/call-Dedup/Fudan_DNA_LCL5.sorted.deduped.bam.bai oss://choppy-cromwell-result/test-choppy/wgs_quartettest_renluyao_0827/7a72d0e6-302d-43ca-b6b0-daeaa0236d06/call-Haplotyper/Fudan_DNA_LCL5_hc.vcf LCL5 | |||
| oss://chinese-quartet/quartet-test-data/fastqfiles/Fudan_DNA_LCL6_R1.fastq.gz oss://chinese-quartet/quartet-test-data/fastqfiles/Fudan_DNA_LCL6_R2.fastq.gz oss://choppy-cromwell-result/test-choppy/wgs_quartettest_renluyao_0827/e85d0acb-f750-48b7-87e6-f28766dd16b9/call-Dedup/Fudan_DNA_LCL6.sorted.deduped.bam oss://choppy-cromwell-result/test-choppy/wgs_quartettest_renluyao_0827/e85d0acb-f750-48b7-87e6-f28766dd16b9/call-Dedup/Fudan_DNA_LCL6.sorted.deduped.bam.bai oss://choppy-cromwell-result/test-choppy/wgs_quartettest_renluyao_0827/e85d0acb-f750-48b7-87e6-f28766dd16b9/call-Haplotyper/Fudan_DNA_LCL6_hc.vcf LCL6 | |||
| #read1 #read2 #bam #bai | |||
二进制
pictures/Picture1.png
查看文件
{kind=link}
| 之前 | 之后 |
|---|---|

|
|
| 宽度: 1122 | 高度: 622 | 大小: 240KB |
二进制
pictures/Screen Shot 2019-07-30 at 12.14.00 AM.png
查看文件
{kind=link}
| 之前 | 之后 |
|---|---|
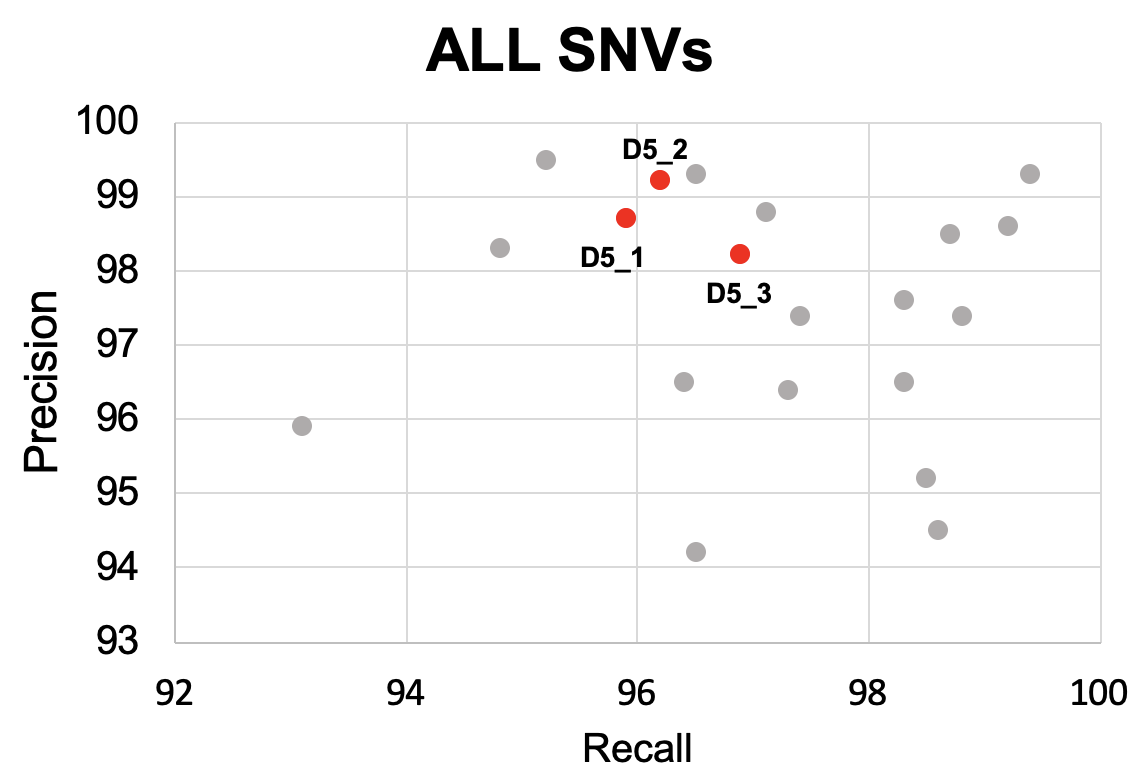
|
|
| 宽度: 1144 | 高度: 772 | 大小: 79KB |
二进制
pictures/Screen Shot 2019-07-31 at 12.40.56 AM.png
查看文件
{kind=link}
| 之前 | 之后 |
|---|---|
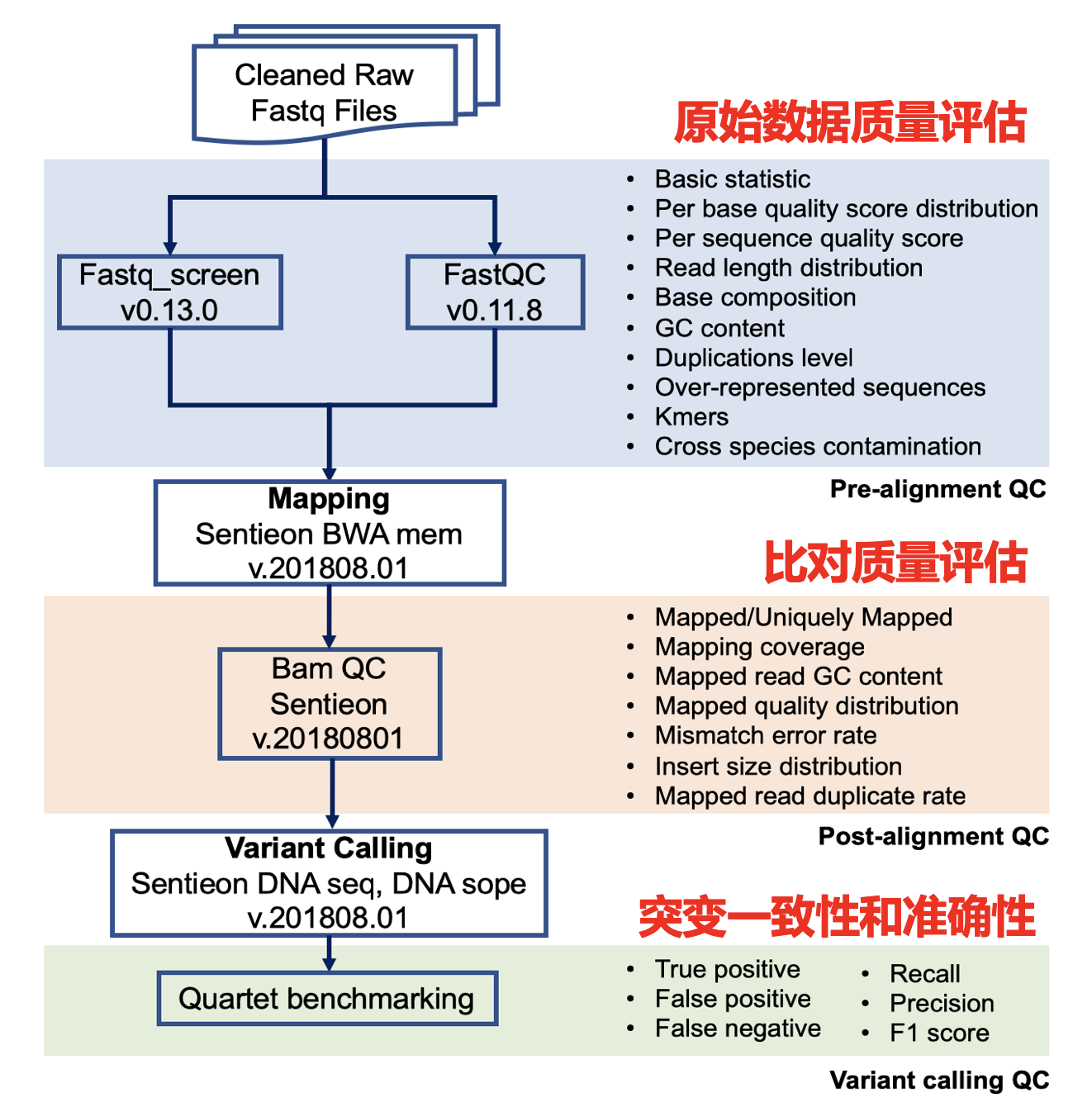
|
|
| 宽度: 1322 | 高度: 1340 | 大小: 502KB |
二进制
pictures/density.png
查看文件
{kind=link}
| 之前 | 之后 |
|---|---|
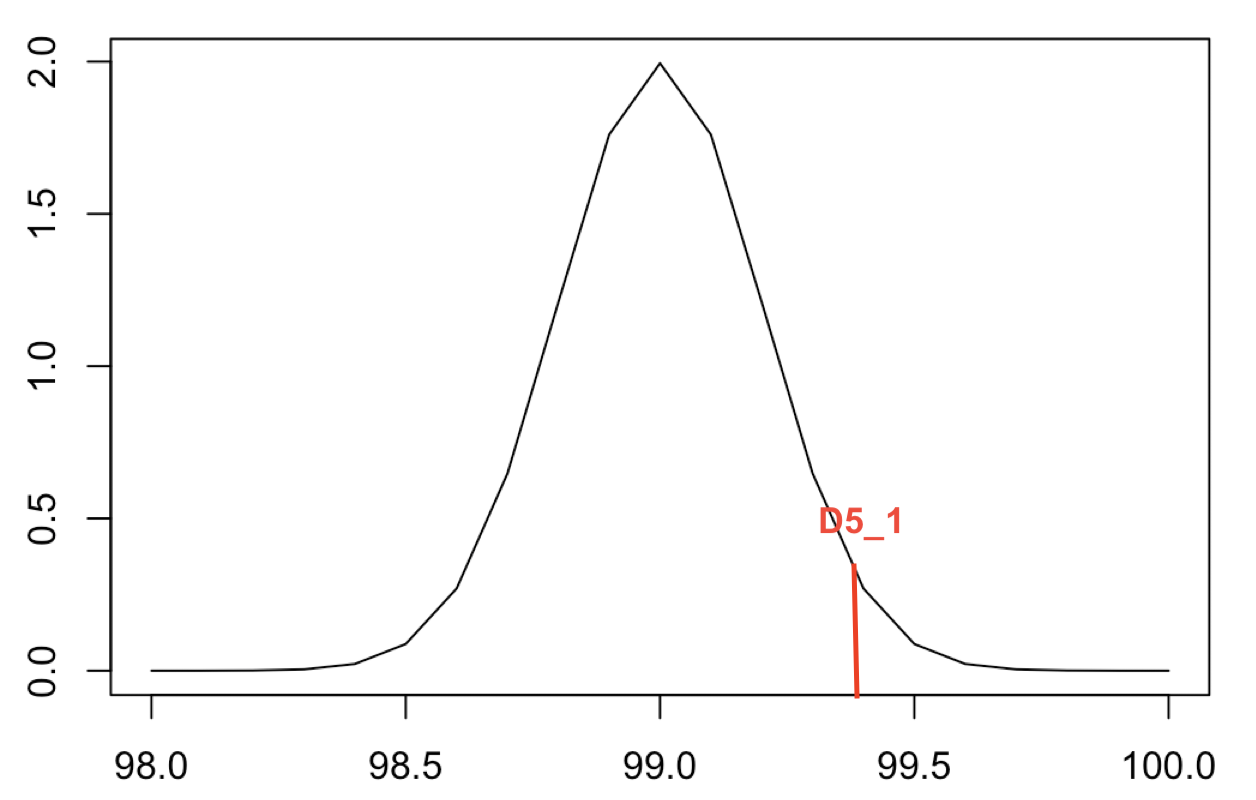
|
|
| 宽度: 1256 | 高度: 800 | 大小: 94KB |
二进制
pictures/workflow2.png
查看文件
{kind=link}
| 之前 | 之后 |
|---|---|
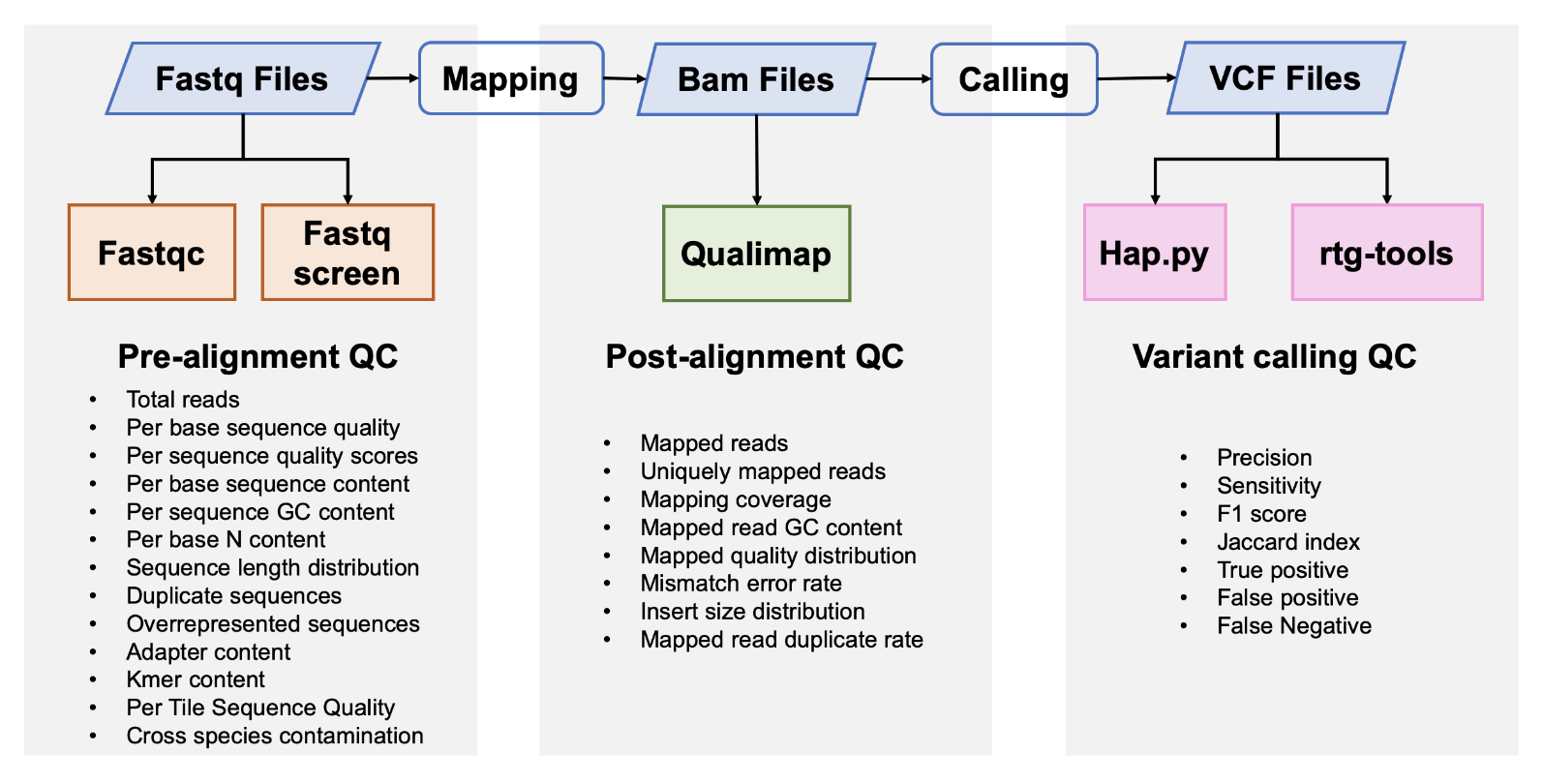
|
|
| 宽度: 1594 | 高度: 810 | 大小: 271KB |
+ 0
- 59
tasks/benchmark.wdl
查看文件
| @@ -1,59 +0,0 @@ | |||
| task benchmark { | |||
| File vcf | |||
| File benchmarking_dir | |||
| File ref_dir | |||
| String sample = basename(vcf,".vcf") | |||
| String sample_mark | |||
| String fasta | |||
| String docker | |||
| String cluster_config | |||
| String disk_size | |||
| command <<< | |||
| set -o pipefail | |||
| set -e | |||
| nt=$(nproc) | |||
| mkdir -p /cromwell_root/tmp | |||
| cp -r ${ref_dir} /cromwell_root/tmp/ | |||
| export HGREF=/cromwell_root/tmp/reference_data/GRCh38.d1.vd1.fa | |||
| /opt/rtg-tools/dist/rtg-tools-3.10.1-4d58ead/rtg bgzip ${vcf} -c > ${sample}.rtg.vcf.gz | |||
| /opt/rtg-tools/dist/rtg-tools-3.10.1-4d58ead/rtg index -f vcf ${sample}.rtg.vcf.gz | |||
| if [ ${sample_mark} == "LCL5" ];then | |||
| /opt/hap.py/bin/hap.py ${benchmarking_dir}/LCL5.vcf.gz ${sample}.rtg.vcf.gz -f ${benchmarking_dir}/LCL5.bed.gz --threads $nt -o ${sample} | |||
| elif [ ${sample_mark} == "LCL6" ]; then | |||
| /opt/hap.py/bin/hap.py ${benchmarking_dir}/LCL6.vcf.gz ${sample}.rtg.vcf.gz -f ${benchmarking_dir}/LCL6.bed.gz --threads $nt -o ${sample} | |||
| elif [ ${sample_mark} == "LCL7" ]; then | |||
| /opt/hap.py/bin/hap.py ${benchmarking_dir}/LCL7.vcf.gz ${sample}.rtg.vcf.gz -f ${benchmarking_dir}/LCL7.bed.gz --threads $nt -o ${sample} | |||
| elif [ ${sample_mark} == "LCL8" ]; then | |||
| /opt/hap.py/bin/hap.py ${benchmarking_dir}/LCL8.vcf.gz ${sample}.rtg.vcf.gz -f ${benchmarking_dir}/LCL8.bed.gz --threads $nt -o ${sample} | |||
| else | |||
| echo "only for quartet samples" | |||
| fi | |||
| >>> | |||
| runtime { | |||
| docker:docker | |||
| cluster:cluster_config | |||
| systemDisk:"cloud_ssd 40" | |||
| dataDisk:"cloud_ssd " + disk_size + " /cromwell_root/" | |||
| } | |||
| output { | |||
| File rtg_vcf = "${sample}.rtg.vcf.gz" | |||
| File rtg_vcf_index = "${sample}.rtg.vcf.gz.tbi" | |||
| File gzip_vcf = "${sample}.vcf.gz" | |||
| File gzip_vcf_index = "${sample}.vcf.gz.tbi" | |||
| File roc_all_csv = "${sample}.roc.all.csv.gz" | |||
| File roc_indel = "${sample}.roc.Locations.INDEL.csv.gz" | |||
| File roc_indel_pass = "${sample}.roc.Locations.INDEL.PASS.csv.gz" | |||
| File roc_snp = "${sample}.roc.Locations.SNP.csv.gz" | |||
| File roc_snp_pass = "${sample}.roc.Locations.SNP.PASS.csv.gz" | |||
| File summary = "${sample}.summary.csv" | |||
| File extended = "${sample}.extended.csv" | |||
| File metrics = "${sample}.metrics.json.gz" | |||
| } | |||
| } | |||
+ 0
- 26
tasks/mergeNum.wdl
查看文件
| @@ -1,26 +0,0 @@ | |||
| task mergeNum { | |||
| Array[File] vcfnumber | |||
| String docker | |||
| String cluster_config | |||
| String disk_size | |||
| command <<< | |||
| set -o pipefail | |||
| set -e | |||
| for i in ${sep=" " vcfnumber} | |||
| do | |||
| cat $i | cut -d':' -f2 | tr '\n' '\t' | sed s'/\t$/\n/g' >> vcfstats | |||
| done | |||
| sed '1i\File\tFailed Filters\tPassed Filters\tSNPs\tMNPs\tInsertions\tDeletions\tIndels\tSame as reference\tSNP Transitions/Transversions\tTotal Het/Hom ratio\tSNP Het/Hom ratio\tMNP Het/Hom ratio\tInsertion Het/Hom ratio\tDeletion Het/Hom ratio\tIndel Het/Hom ratio\tInsertion/Deletion ratio\tIndel/SNP+MNP ratio' vcfstats > vcfstats.txt | |||
| >>> | |||
| runtime { | |||
| docker:docker | |||
| cluster:cluster_config | |||
| systemDisk:"cloud_ssd 40" | |||
| dataDisk:"cloud_ssd " + disk_size + " /cromwell_root/" | |||
| } | |||
| output { | |||
| File vcfstat="vcfstats.txt" | |||
| } | |||
| } | |||
+ 0
- 40
tasks/mergeSentieon.wdl
查看文件
| @@ -1,40 +0,0 @@ | |||
| task mergeSentieon { | |||
| Array[File] aln_metrics_header | |||
| Array[File] aln_metrics_data | |||
| Array[File] dedup_metrics_header | |||
| Array[File] dedup_metrics_data | |||
| Array[File] is_metrics_header | |||
| Array[File] is_metrics_data | |||
| Array[File] deduped_coverage_header | |||
| Array[File] deduped_coverage_data | |||
| String docker | |||
| String cluster_config | |||
| String disk_size | |||
| command <<< | |||
| set -o pipefail | |||
| set -e | |||
| cat ${sep=" " aln_metrics_header} | sed -n '1,1p' | cat - ${sep=" " aln_metrics_data} > aln_metrics.txt | |||
| cat ${sep=" " dedup_metrics_header} | sed -n '1,1p' | cat - ${sep=" " dedup_metrics_data} > dedup_metrics.txt | |||
| cat ${sep=" " is_metrics_header} | sed -n '1,1p' | cat - ${sep=" " is_metrics_data} > is_metrics.txt | |||
| cat ${sep=" " deduped_coverage_header} | sed -n '1,1p' | cat - ${sep=" " deduped_coverage_data} > deduped_coverage.txt | |||
| >>> | |||
| runtime { | |||
| docker:docker | |||
| cluster:cluster_config | |||
| systemDisk:"cloud_ssd 40" | |||
| dataDisk:"cloud_ssd " + disk_size + " /cromwell_root/" | |||
| } | |||
| output { | |||
| File aln_metrics_merge = "aln_metrics.txt" | |||
| File dedup_metrics_merge = "dedup_metrics.txt" | |||
| File is_metrics_merge = "is_metrics.txt" | |||
| File deduped_coverage_merge = "deduped_coverage.txt" | |||
| } | |||
| } | |||
+ 0
- 41
tasks/sentieon.wdl
查看文件
| @@ -1,41 +0,0 @@ | |||
| task sentieon { | |||
| File aln_metrics | |||
| File dedup_metrics | |||
| File is_metrics | |||
| File deduped_coverage | |||
| String sample_name | |||
| String docker | |||
| String cluster_config | |||
| String disk_size | |||
| command <<< | |||
| set -o pipefail | |||
| set -e | |||
| cat ${aln_metrics} | sed -n '2,2p' > aln_metrics.header | |||
| cat ${aln_metrics} | sed -n '5,5p' > ${sample_name}.aln_metrics | |||
| cat ${dedup_metrics} | sed -n '2,2p' > dedup_metrics.header | |||
| cat ${dedup_metrics} | sed -n '3,3p' > ${sample_name}.dedup_metrics | |||
| cat ${is_metrics} | sed -n '2,2p' > is_metrics.header | |||
| cat ${is_metrics} | sed -n '3,3p' > ${sample_name}.is_metrics | |||
| cat ${deduped_coverage} | sed -n '1,1p' > deduped_coverage.header | |||
| cat ${deduped_coverage} | sed -n '2,2p' > ${sample_name}.deduped_coverage | |||
| >>> | |||
| runtime { | |||
| docker:docker | |||
| cluster:cluster_config | |||
| systemDisk:"cloud_ssd 40" | |||
| dataDisk:"cloud_ssd " + disk_size + " /cromwell_root/" | |||
| } | |||
| output { | |||
| File aln_metrics_header = "aln_metrics.header" | |||
| File aln_metrics_data = "${sample_name}.aln_metrics" | |||
| File dedup_metrics_header = "dedup_metrics.header" | |||
| File dedup_metrics_data = "${sample_name}.dedup_metrics" | |||
| File is_metrics_header = "is_metrics.header" | |||
| File is_metrics_data = "${sample_name}.is_metrics" | |||
| File deduped_coverage_header = "deduped_coverage.header" | |||
| File deduped_coverage_data = "${sample_name}.deduped_coverage" | |||
| } | |||
| } | |||
+ 0
- 25
tasks/vcfstat.wdl
查看文件
| @@ -1,25 +0,0 @@ | |||
| task vcfstat { | |||
| File rtg_vcf | |||
| File rtg_vcf_index | |||
| String sample_name | |||
| String docker | |||
| String cluster_config | |||
| String disk_size | |||
| command <<< | |||
| set -o pipefail | |||
| set -e | |||
| /opt/rtg-tools/dist/rtg-tools-3.10.1-4d58ead/rtg vcfstats ${rtg_vcf} > ${sample_name}.stats.txt | |||
| >>> | |||
| runtime { | |||
| docker:docker | |||
| cluster:cluster_config | |||
| systemDisk:"cloud_ssd 40" | |||
| dataDisk:"cloud_ssd " + disk_size + " /cromwell_root/" | |||
| } | |||
| output { | |||
| File vcfnumber="${sample_name}.stats.txt" | |||
| } | |||
| } | |||
+ 1
- 23
workflow.wdl
查看文件
| @@ -1,10 +1,7 @@ | |||
| import "./tasks/fastqc.wdl" as fastqc | |||
| import "./tasks/fastqscreen.wdl" as fastqscreen | |||
| import "./tasks/qualimap.wdl" as qualimap | |||
| import "./tasks/sentieon.wdl" as sentieon | |||
| import "./tasks/multiqc.wdl" as multiqc | |||
| import "./tasks/mergeSentieon.wdl" as mergeSentieon | |||
| workflow {{ project_name }} { | |||
| @@ -36,16 +33,8 @@ workflow {{ project_name }} { | |||
| bai=sample[3] | |||
| } | |||
| call sentieon.sentieon as sentieon { | |||
| input: | |||
| aln_metrics=sample[7], | |||
| dedup_metrics=sample[8], | |||
| is_metrics=sample[9], | |||
| deduped_coverage=sample[10], | |||
| sample_name=sample[6] | |||
| } | |||
| } | |||
| call multiqc.multiqc as multiqc { | |||
| input: | |||
| read1_zip=fastqc.read1_zip, | |||
| @@ -55,16 +44,5 @@ workflow {{ project_name }} { | |||
| zip=qualimap.zip | |||
| } | |||
| call mergeSentieon.mergeSentieon as mergeSentieon { | |||
| input: | |||
| aln_metrics_header=sentieon.aln_metrics_header, | |||
| aln_metrics_data=sentieon.aln_metrics_data, | |||
| dedup_metrics_header=sentieon.dedup_metrics_header, | |||
| dedup_metrics_data=sentieon.dedup_metrics_data, | |||
| is_metrics_header=sentieon.is_metrics_header, | |||
| is_metrics_data=sentieon.is_metrics_data, | |||
| deduped_coverage_header=sentieon.deduped_coverage_header, | |||
| deduped_coverage_data=sentieon.deduped_coverage_data | |||
| } | |||
| } | |||
正在加载...