
 LUYAO REN
5 years ago
LUYAO REN
5 years ago
commit
b8aee0c8b0
28 changed files with 2134 additions and 0 deletions
+ 103
- 0
README.md
View File
| @@ -0,0 +1,103 @@ | |||
| #高置信突变位点的整合 | |||
| > Author: Run Luyao | |||
| > | |||
| > E-mail:18110700050@fudan.edu.cn | |||
| > | |||
| > Git:http://choppy.3steps.cn/renluyao/high_confidence_calls_manuscript.git | |||
| > | |||
| > Last Updates: 18/03/2020 | |||
| ## 安装指南 | |||
| ```bash | |||
| # 激活choppy环境 | |||
| source activate choppy | |||
| # 安装app | |||
| choppy install renluyao/high_confidence_calls_manuscript | |||
| ``` | |||
| ## App概述 | |||
| 中华家系1号全基因组高置信small variants(SNVs和Indels)的整合流程。 | |||
| ## 流程与参数 | |||
| ####1. variantsNorm | |||
| 保留chr1-22,X上的突变 | |||
| 用bcftools norm进行突变格式的统一 | |||
| ####2. mendelian | |||
| LCL5、LCL7和LCL8为三口之家,进行trio-analysis,分析符合孟德尔和不符合孟德尔遗传规律的突变位点 | |||
| LCL6、LCL7和LCL8为三口之家,进行trio-analysis,分析符合孟德尔和不符合孟德尔遗传规律的突变位点 | |||
| 得到LCL5和LCL6两个家系合并的vcf文件 | |||
| ####3. zipIndex | |||
| 对LCL5和LCL6两个家系合并的文件压缩和检索引 | |||
| ####4. VCFrename | |||
| 将VBT的输出结果,VCF文件中的MOTHER FATHER CHILD改成对应的样本名 | |||
| ####5. mergeSister | |||
| 将LCL5和LCL6修改过名字后的家系VCF文件合并 | |||
| ####6. reformVCF | |||
| 根据两个三口之家和姐妹的孟德尔遗传的信息,将之前和合并的VCF分解成4个人的vcf,并且包含了家系遗传的信息 | |||
| ####7. familyzipIndex | |||
| 将上一步输出的4个文件进行压缩和检索引 | |||
| ####8. merge | |||
| 将所有注释后的LCL5 vcf文件合并 | |||
| 将所有注释后的LCL6 vcf文件合并 | |||
| 将所有注释后的LCL7 vcf文件合并 | |||
| 将所有注释后的LCL8 vcf文件合并 | |||
| ####9. vote | |||
| 投票选择高置信的突变位点 | |||
| t | |||
| ## App输入变量与输入文件 | |||
| inputSamplesFile的格式如下 | |||
| ```bash | |||
| #LCL5_VCF #LCL6_VCF #LCL7_VCF #LCL8_VCF #LCL5_sampleName #LCL6_sampleName #LCL7_sampleName #LCL8_sampleName #familyName | |||
| ``` | |||
| 最终版的整合文件包括: | |||
| ## App输出文件 | |||
| ## 结果展示与解读 | |||
| ## CHANGELOG | |||
| ## FAQ | |||
BIN
codescripts/.DS_Store
View File
+ 37
- 0
codescripts/Indel_bed.py
View File
| @@ -0,0 +1,37 @@ | |||
| import pandas as pd | |||
| import sys, argparse, os | |||
| mut = pd.read_table('/mnt/pgx_src_data_pool_4/home/renluyao/manuscript/MIE/vcf/mutation_type',header=None) | |||
| outIndel = open(sys.argv[1],'w') | |||
| for row in mut.itertuples(): | |||
| if ',' in row._4: | |||
| alt_seq = row._4.split(',') | |||
| alt_len = [len(i) for i in alt_seq] | |||
| alt = max(alt_len) | |||
| else: | |||
| alt = len(row._4) | |||
| ref = row._3 | |||
| pos = row._2 | |||
| if len(ref) == 1 and alt == 1: | |||
| pass | |||
| elif len(ref) > alt: | |||
| StartPos = int(pos) - 1 | |||
| EndPos = int(pos) + (len(ref) - 1) | |||
| outline_indel = row._1 + '\t' + str(StartPos) + '\t' + str(EndPos) + '\n' | |||
| outIndel.write(outline_indel) | |||
| elif alt > len(ref): | |||
| StartPos = int(pos) - 1 | |||
| EndPos = int(pos) + (alt - 1) | |||
| outline_indel = row._1 + '\t' + str(StartPos) + '\t' + str(EndPos) + '\n' | |||
| outIndel.write(outline_indel) | |||
| elif len(ref) == alt: | |||
| StartPos = int(pos) - 1 | |||
| EndPos = int(pos) + (alt - 1) | |||
| outline_indel = row._1 + '\t' + str(StartPos) + '\t' + str(EndPos) + '\n' | |||
| outIndel.write(outline_indel) | |||
+ 72
- 0
codescripts/bed_region.py
View File
| @@ -0,0 +1,72 @@ | |||
| import pandas as pd | |||
| import sys, argparse, os | |||
| mut = mut = pd.read_table('/mnt/pgx_src_data_pool_4/home/renluyao/manuscript/benchmark_calls/vcf/mutation_type',header=None) | |||
| vote = pd.read_table('/mnt/pgx_src_data_pool_4/home/renluyao/manuscript/benchmark_calls/all_info/benchmark.vote.mendelian.txt',header=None) | |||
| merged_df = pd.merge(vote, mut, how='inner', left_on=[0,1], right_on = [0,1]) | |||
| outFile = open(sys.argv[1],'w') | |||
| outIndel = open(sys.argv[2],'w') | |||
| for row in merged_df.itertuples(): | |||
| #d5 | |||
| if ',' in row._7: | |||
| d5 = row._7.split(',') | |||
| d5_len = [len(i) for i in d5] | |||
| d5_alt = max(d5_len) | |||
| else: | |||
| d5_alt = len(row._7) | |||
| #d6 | |||
| if ',' in row._15: | |||
| d6 = row._15.split(',') | |||
| d6_len = [len(i) for i in d6] | |||
| d6_alt = max(d6_len) | |||
| else: | |||
| d6_alt = len(row._15) | |||
| #f7 | |||
| if ',' in row._23: | |||
| f7 = row._23.split(',') | |||
| f7_len = [len(i) for i in f7] | |||
| f7_alt = max(f7_len) | |||
| else: | |||
| f7_alt = len(row._23) | |||
| #m8 | |||
| if ',' in row._31: | |||
| m8 = row._31.split(',') | |||
| m8_len = [len(i) for i in m8] | |||
| m8_alt = max(m8_len) | |||
| else: | |||
| m8_alt = len(row._31) | |||
| all_length = [d5_alt,d6_alt,f7_alt,m8_alt] | |||
| alt = max(all_length) | |||
| ref = row._35 | |||
| pos = int(row._2) | |||
| if len(ref) == 1 and alt == 1: | |||
| StartPos = int(pos) -1 | |||
| EndPos = int(pos) | |||
| cate = 'SNV' | |||
| elif len(ref) > alt: | |||
| StartPos = int(pos) - 1 | |||
| EndPos = int(pos) + (len(ref) - 1) | |||
| cate = 'INDEL' | |||
| outline_indel = row._1 + '\t' + str(StartPos) + '\t' + str(EndPos) + '\n' | |||
| outIndel.write(outline_indel) | |||
| elif alt > len(ref): | |||
| StartPos = int(pos) - 1 | |||
| EndPos = int(pos) + (alt - 1) | |||
| cate = 'INDEL' | |||
| outline_indel = row._1 + '\t' + str(StartPos) + '\t' + str(EndPos) + '\n' | |||
| outIndel.write(outline_indel) | |||
| elif len(ref) == alt: | |||
| StartPos = int(pos) - 1 | |||
| EndPos = int(pos) + (alt - 1) | |||
| cate = 'INDEL' | |||
| outline_indel = row._1 + '\t' + str(StartPos) + '\t' + str(EndPos) + '\n' | |||
| outIndel.write(outline_indel) | |||
| outline = row._1 + '\t' + str(StartPos) + '\t' + str(EndPos) + '\t' + str(row._2) + '\t' + cate + '\n' | |||
| outFile.write(outline) | |||
+ 67
- 0
codescripts/cluster.sh
View File
| @@ -0,0 +1,67 @@ | |||
| cat benchmark.men.vote.diffbed.lengthlessthan50.txt | awk '{print $1"\t"$2"\t"".""\t"$35"\t"$7"\t.\t.\t.\tGT\t"$6}' | grep -v '0/0' > LCL5.body | |||
| cat benchmark.men.vote.diffbed.lengthlessthan50.txt | awk '{print $1"\t"$2"\t"".""\t"$35"\t"$15"\t.\t.\t.\tGT\t"$14}' | grep -v '0/0' > LCL6.body | |||
| cat benchmark.men.vote.diffbed.lengthlessthan50.txt | awk '{print $1"\t"$2"\t"".""\t"$35"\t"$23"\t.\t.\t.\tGT\t"$22}' | grep -v '0/0'> LCL7.body | |||
| cat benchmark.men.vote.diffbed.lengthlessthan50.txt | awk '{print $1"\t"$2"\t"".""\t"$35"\t"$31"\t.\t.\t.\tGT\t"$30}'| grep -v '0/0' > LCL8.body | |||
| cat header5 LCL5.body > LCL5.beforediffbed.vcf | |||
| cat header6 LCL6.body > LCL6.beforediffbed.vcf | |||
| cat header7 LCL7.body > LCL7.beforediffbed.vcf | |||
| cat header8 LCL8.body > LCL8.beforediffbed.vcf | |||
| rtg bgzip *beforediffbed.vcf | |||
| rtg index *beforediffbed.vcf.gz | |||
| rtg vcffilter -i LCL5.beforediffbed.vcf.gz --exclude-bed=/mnt/pgx_src_data_pool_4/home/renluyao/manuscript/benchmark_calls/MIE/diff.merged.bed -o LCL5.afterfilterdiffbed.vcf.gz | |||
| rtg vcffilter -i LCL6.beforediffbed.vcf.gz --exclude-bed=/mnt/pgx_src_data_pool_4/home/renluyao/manuscript/benchmark_calls/MIE/diff.merged.bed -o LCL6.afterfilterdiffbed.vcf.gz | |||
| rtg vcffilter -i LCL7.beforediffbed.vcf.gz --exclude-bed=/mnt/pgx_src_data_pool_4/home/renluyao/manuscript/benchmark_calls/MIE/diff.merged.bed -o LCL7.afterfilterdiffbed.vcf.gz | |||
| rtg vcffilter -i LCL8.beforediffbed.vcf.gz --exclude-bed=/mnt/pgx_src_data_pool_4/home/renluyao/manuscript/benchmark_calls/MIE/diff.merged.bed -o LCL8.afterfilterdiffbed.vcf.gz | |||
| /mnt/pgx_src_data_pool_4/home/renluyao/softwares/annovar/table_annovar.pl LCL5.beforediffbed.vcf.gz /mnt/pgx_src_data_pool_4/home/renluyao/softwares/annovar/humandb \ | |||
| -buildver hg38 \ | |||
| -out LCL5 \ | |||
| -remove \ | |||
| -protocol 1000g2015aug_all,1000g2015aug_afr,1000g2015aug_amr,1000g2015aug_eas,1000g2015aug_eur,1000g2015aug_sas,clinvar_20190305,gnomad211_genome \ | |||
| -operation f,f,f,f,f,f,f,f \ | |||
| -nastring . \ | |||
| -vcfinput \ | |||
| --thread 8 | |||
| rtg vcfeval -b /mnt/pgx_src_data_pool_4/home/renluyao/Quartet/GIAB/NA12878_HG001/HG001_GRCh38_GIAB_highconf_CG-IllFB-IllGATKHC-Ion-10X-SOLID_CHROM1-X_v.3.3.2_highconf_PGandRTGphasetransfer.vcf.gz -c LCL5.afterfilterdiffbed.vcf.gz -o LCL5_NIST -t /mnt/pgx_src_data_pool_4/home/renluyao/annotation/hg38/GRCh38.d1.vd1.sdf/ | |||
| rtg vcfeval -b /mnt/pgx_src_data_pool_4/home/renluyao/Quartet/GIAB/NA12878_HG001/HG001_GRCh38_GIAB_highconf_CG-IllFB-IllGATKHC-Ion-10X-SOLID_CHROM1-X_v.3.3.2_highconf_PGandRTGphasetransfer.vcf.gz -c LCL6.afterfilterdiffbed.vcf.gz -o LCL6_NIST -t /mnt/pgx_src_data_pool_4/home/renluyao/annotation/hg38/GRCh38.d1.vd1.sdf/ | |||
| rtg vcfeval -b /mnt/pgx_src_data_pool_4/home/renluyao/Quartet/GIAB/NA12878_HG001/HG001_GRCh38_GIAB_highconf_CG-IllFB-IllGATKHC-Ion-10X-SOLID_CHROM1-X_v.3.3.2_highconf_PGandRTGphasetransfer.vcf.gz -c LCL7.afterfilterdiffbed.vcf.gz -o LCL7_NIST -t /mnt/pgx_src_data_pool_4/home/renluyao/annotation/hg38/GRCh38.d1.vd1.sdf/ | |||
| rtg vcfeval -b /mnt/pgx_src_data_pool_4/home/renluyao/Quartet/GIAB/NA12878_HG001/HG001_GRCh38_GIAB_highconf_CG-IllFB-IllGATKHC-Ion-10X-SOLID_CHROM1-X_v.3.3.2_highconf_PGandRTGphasetransfer.vcf.gz -c LCL8.afterfilterdiffbed.vcf.gz -o LCL8_NIST -t /mnt/pgx_src_data_pool_4/home/renluyao/annotation/hg38/GRCh38.d1.vd1.sdf/ | |||
| zcat LCL5.afterfilterdiffbed.vcf.gz | grep -v '#' | awk '{ if ((length($4) == 1) && (length($5) == 1)) { print } }' | wc -l | |||
| zcat LCL6.afterfilterdiffbed.vcf.gz | grep -v '#' | awk '{ if ((length($4) == 1) && (length($5) == 1)) { print } }' | wc -l | |||
| zcat LCL7.afterfilterdiffbed.vcf.gz | grep -v '#' | awk '{ if ((length($4) == 1) && (length($5) == 1)) { print } }' | wc -l | |||
| zcat LCL8.afterfilterdiffbed.vcf.gz | grep -v '#' | awk '{ if ((length($4) == 1) && (length($5) == 1)) { print } }' | wc -l | |||
| zcat LCL5.afterfilterdiffbed.vcf.gz | grep -v '#' | awk '{ if ((length($4) == 1) && (length($5) < 11) && (length($5) > 1)) { print } }' | wc -l | |||
| zcat LCL6.afterfilterdiffbed.vcf.gz | grep -v '#' | awk '{ if ((length($4) == 1) && (length($5) < 11) && (length($5) > 1)) { print } }' | wc -l | |||
| zcat LCL7.afterfilterdiffbed.vcf.gz | grep -v '#' | awk '{ if ((length($4) == 1) && (length($5) < 11) && (length($5) > 1)) { print } }' | wc -l | |||
| zcat LCL8.afterfilterdiffbed.vcf.gz | grep -v '#' | awk '{ if ((length($4) == 1) && (length($5) < 11) && (length($5) > 1)) { print } }' | wc -l | |||
| zcat LCL5.afterfilterdiffbed.vcf.gz | grep -v '#' | awk '{ if ((length($4) == 1) && (length($5) > 10)) { print } }' | wc -l | |||
| zcat LCL6.afterfilterdiffbed.vcf.gz | grep -v '#' | awk '{ if ((length($4) == 1) && (length($5) > 10)) { print } }' | wc -l | |||
| zcat LCL7.afterfilterdiffbed.vcf.gz | grep -v '#' | awk '{ if ((length($4) == 1) && (length($5) > 10)) { print } }' | wc -l | |||
| zcat LCL8.afterfilterdiffbed.vcf.gz | grep -v '#' | awk '{ if ((length($4) == 1) && (length($5) > 10)) { print } }' | wc -l | |||
| bedtools subtract -a LCL5.27.homo_ref.consensus.bed -b /mnt/pgx_src_data_pool_4/home/renluyao/manuscript/benchmark_calls/MIE/diff.merged.bed > LCL5.27.homo_ref.consensus.filtereddiffbed.bed | |||
| bedtools subtract -a LCL6.27.homo_ref.consensus.bed -b /mnt/pgx_src_data_pool_4/home/renluyao/manuscript/benchmark_calls/MIE/diff.merged.bed > LCL6.27.homo_ref.consensus.filtereddiffbed.bed | |||
| bedtools subtract -a LCL7.27.homo_ref.consensus.bed -b /mnt/pgx_src_data_pool_4/home/renluyao/manuscript/benchmark_calls/MIE/diff.merged.bed > LCL7.27.homo_ref.consensus.filtereddiffbed.bed | |||
| bedtools subtract -a LCL8.27.homo_ref.consensus.bed -b /mnt/pgx_src_data_pool_4/home/renluyao/manuscript/benchmark_calls/MIE/diff.merged.bed > LCL8.27.homo_ref.consensus.filtereddiffbed.bed | |||
| python vcf2bed.py LCL5.body LCL5.variants.bed | |||
| python vcf2bed.py LCL6.body LCL6.variants.bed | |||
| python vcf2bed.py LCL7.body LCL7.variants.bed | |||
| python vcf2bed.py LCL8.body LCL8.variants.bed | |||
| cat /mnt/pgx_src_data_pool_4/home/renluyao/manuscript/benchmark_calls/all_info/LCL5.variants.bed | cut -f1,11,12 | cat - LCL5.27.homo_ref.consensus.filtereddiffbed.bed | sort -k1,1 -k2,2n > LCL5.high.confidence.bed | |||
+ 92
- 0
codescripts/extract_vcf_information.py
View File
| @@ -0,0 +1,92 @@ | |||
| import sys,getopt | |||
| import os | |||
| import re | |||
| import fileinput | |||
| import pandas as pd | |||
| def usage(): | |||
| print( | |||
| """ | |||
| Usage: python extract_vcf_information.py -i input_merged_vcf_file -o parsed_file | |||
| This script will extract SNVs and Indels information from the vcf files and output a tab-delimited files. | |||
| Input: | |||
| -i the selected vcf file | |||
| Output: | |||
| -o tab-delimited parsed file | |||
| """) | |||
| # select supported small variants | |||
| def process(oneLine): | |||
| line = oneLine.rstrip() | |||
| strings = line.strip().split('\t') | |||
| infoParsed = parse_INFO(strings[7]) | |||
| formatKeys = strings[8].split(':') | |||
| formatValues = strings[9].split(':') | |||
| for i in range(0,len(formatKeys) -1) : | |||
| if formatKeys[i] == 'AD': | |||
| ra = formatValues[i].split(',') | |||
| infoParsed['RefDP'] = ra[0] | |||
| infoParsed['AltDP'] = ra[1] | |||
| if (int(ra[1]) + int(ra[0])) != 0: | |||
| infoParsed['af'] = float(int(ra[1])/(int(ra[1]) + int(ra[0]))) | |||
| else: | |||
| pass | |||
| else: | |||
| infoParsed[formatKeys[i]] = formatValues[i] | |||
| infoParsed['chromo'] = strings[0] | |||
| infoParsed['pos'] = strings[1] | |||
| infoParsed['id'] = strings[2] | |||
| infoParsed['ref'] = strings[3] | |||
| infoParsed['alt'] = strings[4] | |||
| infoParsed['qual'] = strings[5] | |||
| return infoParsed | |||
| def parse_INFO(info): | |||
| strings = info.strip().split(';') | |||
| keys = [] | |||
| values = [] | |||
| for i in strings: | |||
| kv = i.split('=') | |||
| if kv[0] == 'DB': | |||
| keys.append('DB') | |||
| values.append('1') | |||
| elif kv[0] == 'AF': | |||
| pass | |||
| else: | |||
| keys.append(kv[0]) | |||
| values.append(kv[1]) | |||
| infoDict = dict(zip(keys, values)) | |||
| return infoDict | |||
| opts,args = getopt.getopt(sys.argv[1:],"hi:o:") | |||
| for op,value in opts: | |||
| if op == "-i": | |||
| inputFile=value | |||
| elif op == "-o": | |||
| outputFile=value | |||
| elif op == "-h": | |||
| usage() | |||
| sys.exit() | |||
| if len(sys.argv[1:]) < 3: | |||
| usage() | |||
| sys.exit() | |||
| allDict = [] | |||
| for line in fileinput.input(inputFile): | |||
| m = re.match('^\#',line) | |||
| if m is not None: | |||
| pass | |||
| else: | |||
| oneDict = process(line) | |||
| allDict.append(oneDict) | |||
| allTable = pd.DataFrame(allDict) | |||
| allTable.to_csv(outputFile,sep='\t',index=False) | |||
+ 47
- 0
codescripts/filter_indel_over_50_cluster.py
View File
| @@ -0,0 +1,47 @@ | |||
| import sys,getopt | |||
| from itertools import islice | |||
| over_50_outfile = open("indel_lenth_over_50.txt",'w') | |||
| less_50_outfile = open("benchmark.men.vote.diffbed.lengthlessthan50.txt","w") | |||
| def process(line): | |||
| strings = line.strip().split('\t') | |||
| #d5 | |||
| if ',' in strings[6]: | |||
| d5 = strings[6].split(',') | |||
| d5_len = [len(i) for i in d5] | |||
| d5_alt = max(d5_len) | |||
| else: | |||
| d5_alt = len(strings[6]) | |||
| #d6 | |||
| if ',' in strings[14]: | |||
| d6 = strings[14].split(',') | |||
| d6_len = [len(i) for i in d6] | |||
| d6_alt = max(d6_len) | |||
| else: | |||
| d6_alt = len(strings[14]) | |||
| #f7 | |||
| if ',' in strings[22]: | |||
| f7 = strings[22].split(',') | |||
| f7_len = [len(i) for i in f7] | |||
| f7_alt = max(f7_len) | |||
| else: | |||
| f7_alt = len(strings[22]) | |||
| #m8 | |||
| if ',' in strings[30]: | |||
| m8 = strings[30].split(',') | |||
| m8_len = [len(i) for i in m8] | |||
| m8_alt = max(m8_len) | |||
| else: | |||
| m8_alt = len(strings[30]) | |||
| #ref | |||
| ref_len = len(strings[34]) | |||
| if (d5_alt > 50) or (d6_alt > 50) or (f7_alt > 50) or (m8_alt > 50) or (ref_len > 50): | |||
| over_50_outfile.write(line) | |||
| else: | |||
| less_50_outfile.write(line) | |||
| input_file = open(sys.argv[1]) | |||
| for line in islice(input_file, 1, None): | |||
| process(line) | |||
+ 43
- 0
codescripts/filter_indel_over_50_mendelian.py
View File
| @@ -0,0 +1,43 @@ | |||
| from itertools import islice | |||
| import fileinput | |||
| import sys, argparse, os | |||
| # input arguments | |||
| parser = argparse.ArgumentParser(description="this script is to exclude indel over 50bp") | |||
| parser.add_argument('-i', '--mergedGVCF', type=str, help='merged gVCF txt with only chr, pos, ref, alt and genotypes', required=True) | |||
| parser.add_argument('-prefix', '--prefix', type=str, help='prefix of output file', required=True) | |||
| args = parser.parse_args() | |||
| input_dat = args.mergedGVCF | |||
| prefix = args.prefix | |||
| # output file | |||
| output_name = prefix + '.indel.lessthan50bp.txt' | |||
| outfile = open(output_name,'w') | |||
| def process(line): | |||
| strings = line.strip().split('\t') | |||
| #d5 | |||
| if ',' in strings[3]: | |||
| alt = strings[3].split(',') | |||
| alt_len = [len(i) for i in alt] | |||
| alt_max = max(alt_len) | |||
| else: | |||
| alt_max = len(strings[3]) | |||
| #ref | |||
| ref_len = len(strings[2]) | |||
| if (alt_max > 50) or (ref_len > 50): | |||
| pass | |||
| else: | |||
| outfile.write(line) | |||
| for line in fileinput.input(input_dat): | |||
| process(line) | |||
+ 416
- 0
codescripts/high_confidence_call_vote.py
View File
| @@ -0,0 +1,416 @@ | |||
| from __future__ import division | |||
| import sys, argparse, os | |||
| import fileinput | |||
| import re | |||
| import pandas as pd | |||
| from operator import itemgetter | |||
| from collections import Counter | |||
| from itertools import islice | |||
| from numpy import * | |||
| import statistics | |||
| # input arguments | |||
| parser = argparse.ArgumentParser(description="this script is to count voting number") | |||
| parser.add_argument('-vcf', '--multi_sample_vcf', type=str, help='The VCF file you want to count the voting number', required=True) | |||
| parser.add_argument('-dup', '--dup_list', type=str, help='Duplication list', required=True) | |||
| parser.add_argument('-sample', '--sample_name', type=str, help='which sample of quartet', required=True) | |||
| parser.add_argument('-prefix', '--prefix', type=str, help='Prefix of output file name', required=True) | |||
| args = parser.parse_args() | |||
| multi_sample_vcf = args.multi_sample_vcf | |||
| dup_list = args.dup_list | |||
| prefix = args.prefix | |||
| sample_name = args.sample_name | |||
| vcf_header = '''##fileformat=VCFv4.2 | |||
| ##fileDate=20200331 | |||
| ##source=high_confidence_calls_intergration(choppy app) | |||
| ##reference=GRCh38.d1.vd1 | |||
| ##INFO=<ID=location,Number=1,Type=String,Description="Repeat region"> | |||
| ##INFO=<ID=DETECTED,Number=1,Type=Integer,Description="Number of detected votes"> | |||
| ##INFO=<ID=VOTED,Number=1,Type=Integer,Description="Number of consnesus votes"> | |||
| ##INFO=<ID=FAM,Number=1,Type=Integer,Description="Number mendelian consisitent votes"> | |||
| ##FORMAT=<ID=GT,Number=1,Type=String,Description="Genotype"> | |||
| ##FORMAT=<ID=DP,Number=1,Type=Integer,Description="Sum depth of all samples"> | |||
| ##FORMAT=<ID=ALT,Number=1,Type=Integer,Description="Sum alternative depth of all samples"> | |||
| ##FORMAT=<ID=AF,Number=1,Type=Float,Description="Allele frequency, sum alternative depth / sum depth"> | |||
| ##FORMAT=<ID=GQ,Number=1,Type=Float,Description="Average genotype quality"> | |||
| ##FORMAT=<ID=QD,Number=1,Type=Float,Description="Average Variant Confidence/Quality by Depth"> | |||
| ##FORMAT=<ID=MQ,Number=1,Type=Float,Description="Average mapping quality"> | |||
| ##FORMAT=<ID=FS,Number=1,Type=Float,Description="Average Phred-scaled p-value using Fisher's exact test to detect strand bias"> | |||
| ##FORMAT=<ID=QUALI,Number=1,Type=Float,Description="Average variant quality"> | |||
| ##contig=<ID=chr1,length=248956422> | |||
| ##contig=<ID=chr2,length=242193529> | |||
| ##contig=<ID=chr3,length=198295559> | |||
| ##contig=<ID=chr4,length=190214555> | |||
| ##contig=<ID=chr5,length=181538259> | |||
| ##contig=<ID=chr6,length=170805979> | |||
| ##contig=<ID=chr7,length=159345973> | |||
| ##contig=<ID=chr8,length=145138636> | |||
| ##contig=<ID=chr9,length=138394717> | |||
| ##contig=<ID=chr10,length=133797422> | |||
| ##contig=<ID=chr11,length=135086622> | |||
| ##contig=<ID=chr12,length=133275309> | |||
| ##contig=<ID=chr13,length=114364328> | |||
| ##contig=<ID=chr14,length=107043718> | |||
| ##contig=<ID=chr15,length=101991189> | |||
| ##contig=<ID=chr16,length=90338345> | |||
| ##contig=<ID=chr17,length=83257441> | |||
| ##contig=<ID=chr18,length=80373285> | |||
| ##contig=<ID=chr19,length=58617616> | |||
| ##contig=<ID=chr20,length=64444167> | |||
| ##contig=<ID=chr21,length=46709983> | |||
| ##contig=<ID=chr22,length=50818468> | |||
| ##contig=<ID=chrX,length=156040895> | |||
| ''' | |||
| vcf_header_all_sample = '''##fileformat=VCFv4.2 | |||
| ##fileDate=20200331 | |||
| ##reference=GRCh38.d1.vd1 | |||
| ##INFO=<ID=location,Number=1,Type=String,Description="Repeat region"> | |||
| ##INFO=<ID=DUP,Number=1,Type=Flag,Description="Duplicated variant records"> | |||
| ##INFO=<ID=DETECTED,Number=1,Type=Integer,Description="Number of detected votes"> | |||
| ##INFO=<ID=VOTED,Number=1,Type=Integer,Description="Number of consnesus votes"> | |||
| ##INFO=<ID=FAM,Number=1,Type=Integer,Description="Number mendelian consisitent votes"> | |||
| ##INFO=<ID=ALL_ALT,Number=1,Type=Float,Description="Sum of alternative reads of all samples"> | |||
| ##INFO=<ID=ALL_DP,Number=1,Type=Float,Description="Sum of depth of all samples"> | |||
| ##INFO=<ID=ALL_AF,Number=1,Type=Float,Description="Allele frequency of net alternatice reads and net depth"> | |||
| ##INFO=<ID=GQ_MEAN,Number=1,Type=Float,Description="Mean of genotype quality of all samples"> | |||
| ##INFO=<ID=QD_MEAN,Number=1,Type=Float,Description="Average Variant Confidence/Quality by Depth"> | |||
| ##INFO=<ID=MQ_MEAN,Number=1,Type=Float,Description="Mean of mapping quality of all samples"> | |||
| ##INFO=<ID=FS_MEAN,Number=1,Type=Float,Description="Average Phred-scaled p-value using Fisher's exact test to detect strand bias"> | |||
| ##INFO=<ID=QUAL_MEAN,Number=1,Type=Float,Description="Average variant quality"> | |||
| ##INFO=<ID=PCR,Number=1,Type=String,Description="Consensus of PCR votes"> | |||
| ##INFO=<ID=PCR_FREE,Number=1,Type=String,Description="Consensus of PCR-free votes"> | |||
| ##INFO=<ID=CONSENSUS,Number=1,Type=String,Description="Consensus calls"> | |||
| ##INFO=<ID=CONSENSUS_SEQ,Number=1,Type=String,Description="Consensus sequence"> | |||
| ##FORMAT=<ID=GT,Number=1,Type=String,Description="Genotype"> | |||
| ##FORMAT=<ID=DP,Number=1,Type=String,Description="Depth"> | |||
| ##FORMAT=<ID=ALT,Number=1,Type=Integer,Description="Alternative Depth"> | |||
| ##FORMAT=<ID=AF,Number=1,Type=String,Description="Allele frequency"> | |||
| ##FORMAT=<ID=GQ,Number=1,Type=String,Description="Genotype quality"> | |||
| ##FORMAT=<ID=MQ,Number=1,Type=String,Description="Mapping quality"> | |||
| ##FORMAT=<ID=TWINS,Number=1,Type=String,Description="1 is twins shared, 0 is twins discordant "> | |||
| ##FORMAT=<ID=TRIO5,Number=1,Type=String,Description="1 is LCL7, LCL8 and LCL5 mendelian consistent, 0 is mendelian vioaltion"> | |||
| ##FORMAT=<ID=TRIO6,Number=1,Type=String,Description="1 is LCL7, LCL8 and LCL6 mendelian consistent, 0 is mendelian vioaltion"> | |||
| ##contig=<ID=chr1,length=248956422> | |||
| ##contig=<ID=chr2,length=242193529> | |||
| ##contig=<ID=chr3,length=198295559> | |||
| ##contig=<ID=chr4,length=190214555> | |||
| ##contig=<ID=chr5,length=181538259> | |||
| ##contig=<ID=chr6,length=170805979> | |||
| ##contig=<ID=chr7,length=159345973> | |||
| ##contig=<ID=chr8,length=145138636> | |||
| ##contig=<ID=chr9,length=138394717> | |||
| ##contig=<ID=chr10,length=133797422> | |||
| ##contig=<ID=chr11,length=135086622> | |||
| ##contig=<ID=chr12,length=133275309> | |||
| ##contig=<ID=chr13,length=114364328> | |||
| ##contig=<ID=chr14,length=107043718> | |||
| ##contig=<ID=chr15,length=101991189> | |||
| ##contig=<ID=chr16,length=90338345> | |||
| ##contig=<ID=chr17,length=83257441> | |||
| ##contig=<ID=chr18,length=80373285> | |||
| ##contig=<ID=chr19,length=58617616> | |||
| ##contig=<ID=chr20,length=64444167> | |||
| ##contig=<ID=chr21,length=46709983> | |||
| ##contig=<ID=chr22,length=50818468> | |||
| ##contig=<ID=chrX,length=156040895> | |||
| ''' | |||
| # read in duplication list | |||
| dup = pd.read_table(dup_list,header=None) | |||
| var_dup = dup[0].tolist() | |||
| # output file | |||
| benchmark_file_name = prefix + '_voted.vcf' | |||
| benchmark_outfile = open(benchmark_file_name,'w') | |||
| all_sample_file_name = prefix + '_all_sample_information.vcf' | |||
| all_sample_outfile = open(all_sample_file_name,'w') | |||
| # write VCF | |||
| outputcolumn = '#CHROM\tPOS\tID\tREF\tALT\tQUAL\tFILTER\tINFO\tFORMAT\t' + sample_name + '_benchmark_calls\n' | |||
| benchmark_outfile.write(vcf_header) | |||
| benchmark_outfile.write(outputcolumn) | |||
| outputcolumn_all_sample = '#CHROM\tPOS\tID\tREF\tALT\tQUAL\tFILTER\tINFO\tFORMAT\t'+ \ | |||
| 'Quartet_DNA_BGI_SEQ2000_BGI_1_20180518\tQuartet_DNA_BGI_SEQ2000_BGI_2_20180530\tQuartet_DNA_BGI_SEQ2000_BGI_3_20180530\t' + \ | |||
| 'Quartet_DNA_BGI_T7_WGE_1_20191105\tQuartet_DNA_BGI_T7_WGE_2_20191105\tQuartet_DNA_BGI_T7_WGE_3_20191105\t' + \ | |||
| 'Quartet_DNA_ILM_Nova_ARD_1_20181108\tQuartet_DNA_ILM_Nova_ARD_2_20181108\tQuartet_DNA_ILM_Nova_ARD_3_20181108\t' + \ | |||
| 'Quartet_DNA_ILM_Nova_ARD_4_20190111\tQuartet_DNA_ILM_Nova_ARD_5_20190111\tQuartet_DNA_ILM_Nova_ARD_6_20190111\t' + \ | |||
| 'Quartet_DNA_ILM_Nova_BRG_1_20180930\tQuartet_DNA_ILM_Nova_BRG_2_20180930\tQuartet_DNA_ILM_Nova_BRG_3_20180930\t' + \ | |||
| 'Quartet_DNA_ILM_Nova_WUX_1_20190917\tQuartet_DNA_ILM_Nova_WUX_2_20190917\tQuartet_DNA_ILM_Nova_WUX_3_20190917\t' + \ | |||
| 'Quartet_DNA_ILM_XTen_ARD_1_20170403\tQuartet_DNA_ILM_XTen_ARD_2_20170403\tQuartet_DNA_ILM_XTen_ARD_3_20170403\t' + \ | |||
| 'Quartet_DNA_ILM_XTen_NVG_1_20170329\tQuartet_DNA_ILM_XTen_NVG_2_20170329\tQuartet_DNA_ILM_XTen_NVG_3_20170329\t' + \ | |||
| 'Quartet_DNA_ILM_XTen_WUX_1_20170216\tQuartet_DNA_ILM_XTen_WUX_2_20170216\tQuartet_DNA_ILM_XTen_WUX_3_20170216\n' | |||
| all_sample_outfile.write(vcf_header_all_sample) | |||
| all_sample_outfile.write(outputcolumn_all_sample) | |||
| #function | |||
| def replace_nan(strings_list): | |||
| updated_list = [] | |||
| for i in strings_list: | |||
| if i == '.': | |||
| updated_list.append('.:.:.:.:.:.:.:.:.:.:.:.') | |||
| else: | |||
| updated_list.append(i) | |||
| return updated_list | |||
| def remove_dot(strings_list): | |||
| updated_list = [] | |||
| for i in strings_list: | |||
| if i == '.': | |||
| pass | |||
| else: | |||
| updated_list.append(i) | |||
| return updated_list | |||
| def detected_number(strings): | |||
| gt = [x.split(':')[0] for x in strings] | |||
| percentage = 27 - gt.count('.') | |||
| return(str(percentage)) | |||
| def vote_number(strings,consensus_call): | |||
| gt = [x.split(':')[0] for x in strings] | |||
| gt = [x.replace('.','0/0') for x in gt] | |||
| gt = list(map(gt_uniform,[i for i in gt])) | |||
| vote_num = gt.count(consensus_call) | |||
| return(str(vote_num)) | |||
| def family_vote(strings,consensus_call): | |||
| gt = [x.split(':')[0] for x in strings] | |||
| gt = [x.replace('.','0/0') for x in gt] | |||
| gt = list(map(gt_uniform,[i for i in gt])) | |||
| mendelian = [':'.join(x.split(':')[1:4]) for x in strings] | |||
| indices = [i for i, x in enumerate(gt) if x == consensus_call] | |||
| matched_mendelian = itemgetter(*indices)(mendelian) | |||
| mendelian_num = matched_mendelian.count('1:1:1') | |||
| return(str(mendelian_num)) | |||
| def gt_uniform(strings): | |||
| uniformed_gt = '' | |||
| allele1 = strings.split('/')[0] | |||
| allele2 = strings.split('/')[1] | |||
| if int(allele1) > int(allele2): | |||
| uniformed_gt = allele2 + '/' + allele1 | |||
| else: | |||
| uniformed_gt = allele1 + '/' + allele2 | |||
| return uniformed_gt | |||
| def decide_by_rep(strings): | |||
| consensus_rep = '' | |||
| mendelian = [':'.join(x.split(':')[1:4]) for x in strings] | |||
| gt = [x.split(':')[0] for x in strings] | |||
| gt = [x.replace('.','0/0') for x in gt] | |||
| # modified gt turn 2/1 to 1/2 | |||
| gt = list(map(gt_uniform,[i for i in gt])) | |||
| # mendelian consistent? | |||
| mendelian_dict = Counter(mendelian) | |||
| highest_mendelian = mendelian_dict.most_common(1) | |||
| candidate_mendelian = highest_mendelian[0][0] | |||
| freq_mendelian = highest_mendelian[0][1] | |||
| if (candidate_mendelian == '1:1:1') and (freq_mendelian >= 2): | |||
| gt_num_dict = Counter(gt) | |||
| highest_gt = gt_num_dict.most_common(1) | |||
| candidate_gt = highest_gt[0][0] | |||
| freq_gt = highest_gt[0][1] | |||
| if (candidate_gt != '0/0') and (freq_gt >= 2): | |||
| consensus_rep = candidate_gt | |||
| elif (candidate_gt == '0/0') and (freq_gt >= 2): | |||
| consensus_rep = '0/0' | |||
| else: | |||
| consensus_rep = 'inconGT' | |||
| elif (candidate_mendelian == '') and (freq_mendelian >= 2): | |||
| consensus_rep = 'noInfo' | |||
| else: | |||
| consensus_rep = 'inconMen' | |||
| return consensus_rep | |||
| def main(): | |||
| for line in fileinput.input(multi_sample_vcf): | |||
| headline = re.match('^\#',line) | |||
| if headline is not None: | |||
| pass | |||
| else: | |||
| line = line.strip() | |||
| strings = line.split('\t') | |||
| variant_id = '_'.join([strings[0],strings[1]]) | |||
| # check if the variants location is duplicated | |||
| if variant_id in var_dup: | |||
| strings[7] = strings[7] + ';DUP' | |||
| outLine = '\t'.join(strings) + '\n' | |||
| all_sample_outfile.write(outLine) | |||
| else: | |||
| # pre-define | |||
| pcr_consensus = '.' | |||
| pcr_free_consensus = '.' | |||
| consensus_call = '.' | |||
| consensus_alt_seq = '.' | |||
| # pcr | |||
| strings[9:] = replace_nan(strings[9:]) | |||
| pcr = itemgetter(*[9,10,11,27,28,29,30,31,32,33,34,35])(strings) | |||
| SEQ2000 = decide_by_rep(pcr[0:3]) | |||
| XTen_ARD = decide_by_rep(pcr[3:6]) | |||
| XTen_NVG = decide_by_rep(pcr[6:9]) | |||
| XTen_WUX = decide_by_rep(pcr[9:12]) | |||
| sequence_site = [SEQ2000,XTen_ARD,XTen_NVG,XTen_WUX] | |||
| sequence_dict = Counter(sequence_site) | |||
| highest_sequence = sequence_dict.most_common(1) | |||
| candidate_sequence = highest_sequence[0][0] | |||
| freq_sequence = highest_sequence[0][1] | |||
| if freq_sequence > 2: | |||
| pcr_consensus = candidate_sequence | |||
| else: | |||
| pcr_consensus = 'inconSequenceSite' | |||
| # pcr-free | |||
| pcr_free = itemgetter(*[12,13,14,15,16,17,18,19,20,21,22,23,24,25,26])(strings) | |||
| T7_WGE = decide_by_rep(pcr_free[0:3]) | |||
| Nova_ARD_1 = decide_by_rep(pcr_free[3:6]) | |||
| Nova_ARD_2 = decide_by_rep(pcr_free[6:9]) | |||
| Nova_BRG = decide_by_rep(pcr_free[9:12]) | |||
| Nova_WUX = decide_by_rep(pcr_free[12:15]) | |||
| sequence_site = [T7_WGE,Nova_ARD_1,Nova_ARD_2,Nova_BRG,Nova_WUX] | |||
| highest_sequence = sequence_dict.most_common(1) | |||
| candidate_sequence = highest_sequence[0][0] | |||
| freq_sequence = highest_sequence[0][1] | |||
| if freq_sequence > 3: | |||
| pcr_free_consensus = candidate_sequence | |||
| else: | |||
| pcr_free_consensus = 'inconSequenceSite' | |||
| # pcr and pcr-free | |||
| tag = ['inconGT','noInfo','inconMen','inconSequenceSite'] | |||
| if (pcr_consensus == pcr_free_consensus) and (pcr_consensus not in tag) and (pcr_consensus != '0/0'): | |||
| consensus_call = pcr_consensus | |||
| VOTED = vote_number(strings[9:],consensus_call) | |||
| strings[7] = strings[7] + ';VOTED=' + VOTED | |||
| DETECTED = detected_number(strings[9:]) | |||
| strings[7] = strings[7] + ';DETECTED=' + DETECTED | |||
| FAM = family_vote(strings[9:],consensus_call) | |||
| strings[7] = strings[7] + ';FAM=' + FAM | |||
| # Delete multiple alternative genotype to necessary expression | |||
| alt = strings[4] | |||
| alt_gt = alt.split(',') | |||
| if len(alt_gt) > 1: | |||
| allele1 = consensus_call.split('/')[0] | |||
| allele2 = consensus_call.split('/')[1] | |||
| if allele1 == '0': | |||
| allele2_seq = alt_gt[int(allele2) - 1] | |||
| consensus_alt_seq = allele2_seq | |||
| consensus_call = '0/1' | |||
| else: | |||
| allele1_seq = alt_gt[int(allele1) - 1] | |||
| allele2_seq = alt_gt[int(allele2) - 1] | |||
| if int(allele1) > int(allele2): | |||
| consensus_alt_seq = allele2_seq + ',' + allele1_seq | |||
| consensus_call = '1/2' | |||
| elif int(allele1) < int(allele2): | |||
| consensus_alt_seq = allele1_seq + ',' + allele2_seq | |||
| consensus_call = '1/2' | |||
| else: | |||
| consensus_alt_seq = allele1_seq | |||
| consensus_call = '1/1' | |||
| else: | |||
| consensus_alt_seq = alt | |||
| # GT:DP:ALT:AF:GQ:QD:MQ:FS:QUAL | |||
| # GT:TWINS:TRIO5:TRIO6:DP:ALT:AF:GQ:QD:MQ:FS:QUAL:rawGT | |||
| # DP | |||
| DP = [x.split(':')[4] for x in strings[9:]] | |||
| DP = remove_dot(DP) | |||
| DP = [int(x) for x in DP] | |||
| ALL_DP = sum(DP) | |||
| # AF | |||
| ALT = [x.split(':')[5] for x in strings[9:]] | |||
| ALT = remove_dot(ALT) | |||
| ALT = [int(x) for x in ALT] | |||
| ALL_ALT = sum(ALT) | |||
| ALL_AF = round(ALL_ALT/ALL_DP,2) | |||
| # GQ | |||
| GQ = [x.split(':')[7] for x in strings[9:]] | |||
| GQ = remove_dot(GQ) | |||
| GQ = [int(x) for x in GQ] | |||
| GQ_MEAN = round(mean(GQ),2) | |||
| # QD | |||
| QD = [x.split(':')[8] for x in strings[9:]] | |||
| QD = remove_dot(QD) | |||
| QD = [float(x) for x in QD] | |||
| QD_MEAN = round(mean(QD),2) | |||
| # MQ | |||
| MQ = [x.split(':')[9] for x in strings[9:]] | |||
| MQ = remove_dot(MQ) | |||
| MQ = [float(x) for x in MQ] | |||
| MQ_MEAN = round(mean(MQ),2) | |||
| # FS | |||
| FS = [x.split(':')[10] for x in strings[9:]] | |||
| FS = remove_dot(FS) | |||
| FS = [float(x) for x in FS] | |||
| FS_MEAN = round(mean(FS),2) | |||
| # QUAL | |||
| QUAL = [x.split(':')[11] for x in strings[9:]] | |||
| QUAL = remove_dot(QUAL) | |||
| QUAL = [float(x) for x in QUAL] | |||
| QUAL_MEAN = round(mean(QUAL),2) | |||
| # benchmark output | |||
| output_format = consensus_call + ':' + str(ALL_DP) + ':' + str(ALL_ALT) + ':' + str(ALL_AF) + ':' + str(GQ_MEAN) + ':' + str(QD_MEAN) + ':' + str(MQ_MEAN) + ':' + str(FS_MEAN) + ':' + str(QUAL_MEAN) | |||
| outLine = strings[0] + '\t' + strings[1] + '\t' + strings[2] + '\t' + strings[3] + '\t' + consensus_alt_seq + '\t' + '.' + '\t' + '.' + '\t' + strings[7] + '\t' + 'GT:DP:ALT:AF:GQ:QD:MQ:FS:QUAL' + '\t' + output_format + '\n' | |||
| benchmark_outfile.write(outLine) | |||
| # all sample output | |||
| strings[7] = strings[7] + ';ALL_ALT=' + str(ALL_ALT) + ';ALL_DP=' + str(ALL_DP) + ';ALL_AF=' + str(ALL_AF) \ | |||
| + ';GQ_MEAN=' + str(GQ_MEAN) + ';QD_MEAN=' + str(QD_MEAN) + ';MQ_MEAN=' + str(MQ_MEAN) + ';FS_MEAN=' + str(FS_MEAN) \ | |||
| + ';QUAL_MEAN=' + str(QUAL_MEAN) + ';PCR=' + consensus_call + ';PCR_FREE=' + consensus_call + ';CONSENSUS=' + consensus_call \ | |||
| + ';CONSENSUS_SEQ=' + consensus_alt_seq | |||
| all_sample_outLine = '\t'.join(strings) + '\n' | |||
| all_sample_outfile.write(all_sample_outLine) | |||
| elif (pcr_consensus in tag) and (pcr_free_consensus in tag): | |||
| consensus_call = 'filtered' | |||
| DETECTED = detected_number(strings[9:]) | |||
| strings[7] = strings[7] + ';DETECTED=' + DETECTED | |||
| strings[7] = strings[7] + ';CONSENSUS=' + consensus_call | |||
| all_sample_outLine = '\t'.join(strings) + '\n' | |||
| all_sample_outfile.write(all_sample_outLine) | |||
| elif ((pcr_consensus == '0/0') or (pcr_consensus in tag)) and ((pcr_free_consensus not in tag) and (pcr_free_consensus != '0/0')): | |||
| consensus_call = 'pcr-free-speicifc' | |||
| DETECTED = detected_number(strings[9:]) | |||
| strings[7] = strings[7] + ';DETECTED=' + DETECTED | |||
| strings[7] = strings[7] + ';CONSENSUS=' + consensus_call | |||
| all_sample_outLine = '\t'.join(strings) + '\n' | |||
| all_sample_outfile.write(all_sample_outLine) | |||
| elif ((pcr_consensus != '0/0') or (pcr_consensus not in tag)) and ((pcr_free_consensus in tag) and (pcr_free_consensus == '0/0')): | |||
| consensus_call = 'pcr-speicifc' | |||
| DETECTED = detected_number(strings[9:]) | |||
| strings[7] = strings[7] + ';DETECTED=' + DETECTED | |||
| strings[7] = strings[7] + ';CONSENSUS=' + consensus_call + ';PCR=' + pcr_consensus + ';PCR_FREE=' + pcr_free_consensus | |||
| all_sample_outLine = '\t'.join(strings) + '\n' | |||
| all_sample_outfile.write(all_sample_outLine) | |||
| elif (pcr_consensus == '0/0') and (pcr_free_consensus == '0/0'): | |||
| consensus_call = 'confirm for parents' | |||
| DETECTED = detected_number(strings[9:]) | |||
| strings[7] = strings[7] + ';DETECTED=' + DETECTED | |||
| strings[7] = strings[7] + ';CONSENSUS=' + consensus_call | |||
| all_sample_outLine = '\t'.join(strings) + '\n' | |||
| all_sample_outfile.write(all_sample_outLine) | |||
| else: | |||
| consensus_call = 'filtered' | |||
| DETECTED = detected_number(strings[9:]) | |||
| strings[7] = strings[7] + ';DETECTED=' + DETECTED | |||
| strings[7] = strings[7] + ';CONSENSUS=' + consensus_call | |||
| all_sample_outLine = '\t'.join(strings) + '\n' | |||
| all_sample_outfile.write(all_sample_outLine) | |||
| if __name__ == '__main__': | |||
| main() | |||
+ 42
- 0
codescripts/lcl5_all_called_variants.py
View File
| @@ -0,0 +1,42 @@ | |||
| from __future__ import division | |||
| import sys, argparse, os | |||
| import pandas as pd | |||
| from collections import Counter | |||
| # input arguments | |||
| parser = argparse.ArgumentParser(description="this script is to merge mendelian and vcfinfo, and extract high_confidence_calls") | |||
| parser.add_argument('-vcf', '--vcf', type=str, help='merged multiple sample vcf', required=True) | |||
| args = parser.parse_args() | |||
| vcf = args.vcf | |||
| lcl5_outfile = open('LCL5_all_variants.txt','w') | |||
| filtered_outfile = open('LCL5_filtered_variants.txt','w') | |||
| vcf_dat = pd.read_table(vcf) | |||
| for row in vcf_dat.itertuples(): | |||
| lcl5_list = [row.Quartet_DNA_BGI_SEQ2000_BGI_LCL5_1_20180518,row.Quartet_DNA_BGI_SEQ2000_BGI_LCL5_2_20180530,row.Quartet_DNA_BGI_SEQ2000_BGI_LCL5_3_20180530, \ | |||
| row.Quartet_DNA_BGI_T7_WGE_LCL5_1_20191105,row.Quartet_DNA_BGI_T7_WGE_LCL5_2_20191105,row.Quartet_DNA_BGI_T7_WGE_LCL5_3_20191105, \ | |||
| row.Quartet_DNA_ILM_Nova_ARD_LCL5_1_20181108,row.Quartet_DNA_ILM_Nova_ARD_LCL5_2_20181108,row.Quartet_DNA_ILM_Nova_ARD_LCL5_3_20181108, \ | |||
| row.Quartet_DNA_ILM_Nova_ARD_LCL5_4_20190111,row.Quartet_DNA_ILM_Nova_ARD_LCL5_5_20190111,row.Quartet_DNA_ILM_Nova_ARD_LCL5_6_20190111, \ | |||
| row.Quartet_DNA_ILM_Nova_BRG_LCL5_1_20180930,row.Quartet_DNA_ILM_Nova_BRG_LCL5_2_20180930,row.Quartet_DNA_ILM_Nova_BRG_LCL5_3_20180930, \ | |||
| row.Quartet_DNA_ILM_Nova_WUX_LCL5_1_20190917,row.Quartet_DNA_ILM_Nova_WUX_LCL5_2_20190917,row.Quartet_DNA_ILM_Nova_WUX_LCL5_3_20190917, \ | |||
| row.Quartet_DNA_ILM_XTen_ARD_LCL5_1_20170403,row.Quartet_DNA_ILM_XTen_ARD_LCL5_2_20170403,row.Quartet_DNA_ILM_XTen_ARD_LCL5_3_20170403, \ | |||
| row.Quartet_DNA_ILM_XTen_NVG_LCL5_1_20170329,row.Quartet_DNA_ILM_XTen_NVG_LCL5_2_20170329,row.Quartet_DNA_ILM_XTen_NVG_LCL5_3_20170329, \ | |||
| row.Quartet_DNA_ILM_XTen_WUX_LCL5_1_20170216,row.Quartet_DNA_ILM_XTen_WUX_LCL5_2_20170216,row.Quartet_DNA_ILM_XTen_WUX_LCL5_3_20170216] | |||
| lcl5_vcf_gt = [x.split(':')[0] for x in lcl5_list] | |||
| lcl5_gt=[item.replace('./.', '0/0') for item in lcl5_vcf_gt] | |||
| gt_dict = Counter(lcl5_gt) | |||
| highest_gt = gt_dict.most_common(1) | |||
| candidate_gt = highest_gt[0][0] | |||
| freq_gt = highest_gt[0][1] | |||
| output = row._1 + '\t' + str(row.POS) + '\t' + '\t'.join(lcl5_gt) + '\n' | |||
| if (candidate_gt == '0/0') and (freq_gt == 27): | |||
| filtered_outfile.write(output) | |||
| else: | |||
| lcl5_outfile.write(output) | |||
+ 5
- 0
codescripts/linux_command.sh
View File
| @@ -0,0 +1,5 @@ | |||
| cat benchmark.men.vote.diffbed.filtered | awk '{print $1"\t"$2"\t"".""\t"$35"\t"$7"\t.\t.\t.\tGT\t"$6}' | grep -v '2_y' > LCL5.body | |||
| cat benchmark.men.vote.diffbed.filtered | awk '{print $1"\t"$2"\t"".""\t"$35"\t"$15"\t.\t.\t.\tGT\t"$14}' | grep -v '2_y' > LCL6.body | |||
| cat benchmark.men.vote.diffbed.filtered | awk '{print $1"\t"$2"\t"".""\t"$35"\t"$23"\t.\t.\t.\tGT\t"$22}' | grep -v '2_y' > LCL7.body | |||
| cat benchmark.men.vote.diffbed.filtered | awk '{print $1"\t"$2"\t"".""\t"$35"\t"$31"\t.\t.\t.\tGT\t"$30}' | grep -v '2_y' > LCL8.body | |||
+ 129
- 0
codescripts/merge_mendelian_vcfinfo.py
View File
| @@ -0,0 +1,129 @@ | |||
| from __future__ import division | |||
| import pandas as pd | |||
| import sys, argparse, os | |||
| import fileinput | |||
| import re | |||
| # input arguments | |||
| parser = argparse.ArgumentParser(description="this script is to get final high confidence calls and information of all replicates") | |||
| parser.add_argument('-vcfInfo', '--vcfInfo', type=str, help='The txt file of variants information, this file is named as prefix__variant_quality_location.txt', required=True) | |||
| parser.add_argument('-mendelianInfo', '--mendelianInfo', type=str, help='The merged mendelian information of all samples', required=True) | |||
| parser.add_argument('-sample', '--sample_name', type=str, help='which sample of quartet', required=True) | |||
| args = parser.parse_args() | |||
| vcfInfo = args.vcfInfo | |||
| mendelianInfo = args.mendelianInfo | |||
| sample_name = args.sample_name | |||
| #GT:TWINS:TRIO5:TRIO6:DP:AF:GQ:QD:MQ:FS:QUAL | |||
| vcf_header = '''##fileformat=VCFv4.2 | |||
| ##fileDate=20200331 | |||
| ##source=high_confidence_calls_intergration(choppy app) | |||
| ##reference=GRCh38.d1.vd1 | |||
| ##FORMAT=<ID=GT,Number=1,Type=String,Description="Genotype"> | |||
| ##FORMAT=<ID=TWINS,Number=1,Type=Flag,Description="1 for sister consistent, 0 for sister different"> | |||
| ##FORMAT=<ID=TRIO5,Number=1,Type=Flag,Description="1 for LCL7, LCL8 and LCL5 mendelian consistent, 0 for family violation"> | |||
| ##FORMAT=<ID=TRIO6,Number=1,Type=Flag,Description="1 for LCL7, LCL8 and LCL6 mendelian consistent, 0 for family violation"> | |||
| ##FORMAT=<ID=DP,Number=1,Type=Integer,Description="Depth"> | |||
| ##FORMAT=<ID=ALT,Number=1,Type=Integer,Description="Alternative Depth"> | |||
| ##FORMAT=<ID=AF,Number=1,Type=Float,Description="Allele frequency"> | |||
| ##FORMAT=<ID=GQ,Number=1,Type=Integer,Description="Genotype quality"> | |||
| ##FORMAT=<ID=QD,Number=1,Type=Float,Description="Variant Confidence/Quality by Depth"> | |||
| ##FORMAT=<ID=MQ,Number=1,Type=Float,Description="Mapping quality"> | |||
| ##FORMAT=<ID=FS,Number=1,Type=Float,Description="Phred-scaled p-value using Fisher's exact test to detect strand bias"> | |||
| ##FORMAT=<ID=QUAL,Number=1,Type=Float,Description="variant quality"> | |||
| ##contig=<ID=chr1,length=248956422> | |||
| ##contig=<ID=chr2,length=242193529> | |||
| ##contig=<ID=chr3,length=198295559> | |||
| ##contig=<ID=chr4,length=190214555> | |||
| ##contig=<ID=chr5,length=181538259> | |||
| ##contig=<ID=chr6,length=170805979> | |||
| ##contig=<ID=chr7,length=159345973> | |||
| ##contig=<ID=chr8,length=145138636> | |||
| ##contig=<ID=chr9,length=138394717> | |||
| ##contig=<ID=chr10,length=133797422> | |||
| ##contig=<ID=chr11,length=135086622> | |||
| ##contig=<ID=chr12,length=133275309> | |||
| ##contig=<ID=chr13,length=114364328> | |||
| ##contig=<ID=chr14,length=107043718> | |||
| ##contig=<ID=chr15,length=101991189> | |||
| ##contig=<ID=chr16,length=90338345> | |||
| ##contig=<ID=chr17,length=83257441> | |||
| ##contig=<ID=chr18,length=80373285> | |||
| ##contig=<ID=chr19,length=58617616> | |||
| ##contig=<ID=chr20,length=64444167> | |||
| ##contig=<ID=chr21,length=46709983> | |||
| ##contig=<ID=chr22,length=50818468> | |||
| ##contig=<ID=chrX,length=156040895> | |||
| ''' | |||
| # output file | |||
| file_name = sample_name + '_mendelian_vcfInfo.vcf' | |||
| outfile = open(file_name,'w') | |||
| outputcolumn = '#CHROM\tPOS\tID\tREF\tALT\tQUAL\tFILTER\tINFO\tFORMAT\t' + sample_name + '\n' | |||
| outfile.write(vcf_header) | |||
| outfile.write(outputcolumn) | |||
| # input files | |||
| vcf_info = pd.read_table(vcfInfo) | |||
| mendelian_info = pd.read_table(mendelianInfo) | |||
| merged_df = pd.merge(vcf_info, mendelian_info, how='outer', left_on=['#CHROM','POS'], right_on = ['#CHROM','POS']) | |||
| merged_df = merged_df.fillna('.') | |||
| # | |||
| def parse_INFO(info): | |||
| strings = info.strip().split(';') | |||
| keys = [] | |||
| values = [] | |||
| for i in strings: | |||
| kv = i.split('=') | |||
| if kv[0] == 'DB': | |||
| keys.append('DB') | |||
| values.append('1') | |||
| else: | |||
| keys.append(kv[0]) | |||
| values.append(kv[1]) | |||
| infoDict = dict(zip(keys, values)) | |||
| return infoDict | |||
| # | |||
| for row in merged_df.itertuples(): | |||
| if row[18] != '.': | |||
| # format | |||
| # GT:TWINS:TRIO5:TRIO6:DP:AF:GQ:QD:MQ:FS:QUAL | |||
| FORMAT_x = row[10].split(':') | |||
| ALT = int(FORMAT_x[1].split(',')[1]) | |||
| if int(FORMAT_x[2]) != 0: | |||
| AF = round(ALT/int(FORMAT_x[2]),2) | |||
| else: | |||
| AF = '.' | |||
| INFO_x = parse_INFO(row.INFO_x) | |||
| if FORMAT_x[2] == '0': | |||
| INFO_x['QD'] = '.' | |||
| else: | |||
| pass | |||
| FORMAT = row[18] + ':' + FORMAT_x[2] + ':' + str(ALT) + ':' + str(AF) + ':' + FORMAT_x[3] + ':' + INFO_x['QD'] + ':' + INFO_x['MQ'] + ':' + INFO_x['FS'] + ':' + str(row.QUAL_x) | |||
| # outline | |||
| outline = row._1 + '\t' + str(row.POS) + '\t' + row.ID_x + '\t' + row.REF_y + '\t' + row.ALT_y + '\t' + '.' + '\t' + '.' + '\t' + '.' + '\t' + 'GT:TWINS:TRIO5:TRIO6:DP:ALT:AF:GQ:QD:MQ:FS:QUAL' + '\t' + FORMAT + '\n' | |||
| else: | |||
| rawGT = row[10].split(':') | |||
| FORMAT_x = row[10].split(':') | |||
| ALT = int(FORMAT_x[1].split(',')[1]) | |||
| if int(FORMAT_x[2]) != 0: | |||
| AF = round(ALT/int(FORMAT_x[2]),2) | |||
| else: | |||
| AF = '.' | |||
| INFO_x = parse_INFO(row.INFO_x) | |||
| if FORMAT_x[2] == '0': | |||
| INFO_x['QD'] = '.' | |||
| else: | |||
| pass | |||
| FORMAT = '.:.:.:.' + ':' + FORMAT_x[2] + ':' + str(ALT) + ':' + str(AF) + ':' + FORMAT_x[3] + ':' + INFO_x['QD'] + ':' + INFO_x['MQ'] + ':' + INFO_x['FS'] + ':' + str(row.QUAL_x) + ':' + rawGT[0] | |||
| # outline | |||
| outline = row._1 + '\t' + str(row.POS) + '\t' + row.ID_x + '\t' + row.REF_x + '\t' + row.ALT_x + '\t' + '.' + '\t' + '.' + '\t' + '.' + '\t' + 'GT:TWINS:TRIO5:TRIO6:DP:ALT:AF:GQ:QD:MQ:FS:QUAL:rawGT' + '\t' + FORMAT + '\n' | |||
| outfile.write(outline) | |||
+ 71
- 0
codescripts/merge_two_family.py
View File
| @@ -0,0 +1,71 @@ | |||
| from __future__ import division | |||
| import pandas as pd | |||
| import sys, argparse, os | |||
| import fileinput | |||
| import re | |||
| # input arguments | |||
| parser = argparse.ArgumentParser(description="this script is to extract mendelian concordance information") | |||
| parser.add_argument('-LCL5', '--LCL5', type=str, help='LCL5 family info', required=True) | |||
| parser.add_argument('-LCL6', '--LCL6', type=str, help='LCL6 family info', required=True) | |||
| parser.add_argument('-family', '--family', type=str, help='family name', required=True) | |||
| args = parser.parse_args() | |||
| lcl5 = args.LCL5 | |||
| lcl6 = args.LCL6 | |||
| family = args.family | |||
| # output file | |||
| family_name = family + '.txt' | |||
| family_file = open(family_name,'w') | |||
| # input files | |||
| lcl5_dat = pd.read_table(lcl5) | |||
| lcl6_dat = pd.read_table(lcl6) | |||
| merged_df = pd.merge(lcl5_dat, lcl6_dat, how='outer', left_on=['#CHROM','POS'], right_on = ['#CHROM','POS']) | |||
| def alt_seq(alt, genotype): | |||
| if genotype == './.': | |||
| seq = './.' | |||
| elif genotype == '0/0': | |||
| seq = '0/0' | |||
| else: | |||
| alt = alt.split(',') | |||
| genotype = genotype.split('/') | |||
| if genotype[0] == '0': | |||
| allele2 = alt[int(genotype[1]) - 1] | |||
| seq = '0/' + allele2 | |||
| else: | |||
| allele1 = alt[int(genotype[0]) - 1] | |||
| allele2 = alt[int(genotype[1]) - 1] | |||
| seq = allele1 + '/' + allele2 | |||
| return seq | |||
| for row in merged_df.itertuples(): | |||
| # correction of multiallele | |||
| if pd.isnull(row.INFO_x) == True or pd.isnull(row.INFO_y) == True: | |||
| mendelian = '.' | |||
| else: | |||
| lcl5_seq = alt_seq(row.ALT_x, row.CHILD_x) | |||
| lcl6_seq = alt_seq(row.ALT_y, row.CHILD_y) | |||
| if lcl5_seq == lcl6_seq: | |||
| mendelian = '1' | |||
| else: | |||
| mendelian = '0' | |||
| if pd.isnull(row.INFO_x) == True: | |||
| mendelian = mendelian + ':.' | |||
| else: | |||
| mendelian = mendelian + ':' + row.INFO_x.split('=')[1] | |||
| if pd.isnull(row.INFO_y) == True: | |||
| mendelian = mendelian + ':.' | |||
| else: | |||
| mendelian = mendelian + ':' + row.INFO_y.split('=')[1] | |||
| outline = row._1 + '\t' + str(row.POS) + '\t' + mendelian + '\n' | |||
| family_file.write(outline) | |||
+ 80
- 0
codescripts/merge_two_family_with_genotype.py
View File
| @@ -0,0 +1,80 @@ | |||
| from __future__ import division | |||
| import pandas as pd | |||
| import sys, argparse, os | |||
| import fileinput | |||
| import re | |||
| # input arguments | |||
| parser = argparse.ArgumentParser(description="this script is to extract mendelian concordance information") | |||
| parser.add_argument('-LCL5', '--LCL5', type=str, help='LCL5 family info', required=True) | |||
| parser.add_argument('-LCL6', '--LCL6', type=str, help='LCL6 family info', required=True) | |||
| parser.add_argument('-genotype', '--genotype', type=str, help='Genotype information of a set of four family members', required=True) | |||
| parser.add_argument('-family', '--family', type=str, help='family name', required=True) | |||
| args = parser.parse_args() | |||
| lcl5 = args.LCL5 | |||
| lcl6 = args.LCL6 | |||
| genotype = args.genotype | |||
| family = args.family | |||
| # output file | |||
| family_name = family + '.txt' | |||
| family_file = open(family_name,'w') | |||
| # input files | |||
| lcl5_dat = pd.read_table(lcl5) | |||
| lcl6_dat = pd.read_table(lcl6) | |||
| genotype_dat = pd.read_table(genotype) | |||
| merged_df = pd.merge(lcl5_dat, lcl6_dat, how='outer', left_on=['#CHROM','POS'], right_on = ['#CHROM','POS']) | |||
| merged_genotype_df = pd.merge(merged_df, genotype_dat, how='outer', left_on=['#CHROM','POS'], right_on = ['#CHROM','POS']) | |||
| merged_genotype_df_sub = merged_genotype_df.iloc[:,[0,1,22,23,24,25,26,27,7,17]] | |||
| merged_genotype_df_sub.columns = ['CHROM', 'POS', 'REF', 'ALT','LCL5','LCL6','LCL7','LCL8', 'TRIO5', 'TRIO6'] | |||
| for row in merged_genotype_df_sub.itertuples(): | |||
| # sister | |||
| if row.LCL5 == row.LCL6: | |||
| if row.LCL5 == './.': | |||
| mendelian = 'noInfo' | |||
| sister_count = "no" | |||
| elif row.LCL5 == '0/0': | |||
| mendelian = 'Ref' | |||
| sister_count = "no" | |||
| else: | |||
| mendelian = '1' | |||
| sister_count = "yes_same" | |||
| else: | |||
| mendelian = '0' | |||
| if (row.LCL5 == './.' or row.LCL5 == '0/0') and (row.LCL6 == './.' or row.LCL6 == '0/0'): | |||
| sister_count = "no" | |||
| else: | |||
| sister_count = "yes_diff" | |||
| # family trio5 | |||
| if row.LCL5 == row. LCL7 == row.LCL8 == './.': | |||
| mendelian = mendelian + ':noInfo' | |||
| elif row.LCL5 == row. LCL7 == row.LCL8 == '0/0': | |||
| mendelian = mendelian + ':Ref' | |||
| elif pd.isnull(row.TRIO5) == True: | |||
| mendelian = mendelian + ':unVBT' | |||
| else: | |||
| mendelian = mendelian + ':' + row.TRIO5.split('=')[1] | |||
| # family trio6 | |||
| if row.LCL6 == row. LCL7 == row.LCL8 == './.': | |||
| mendelian = mendelian + ':noInfo' | |||
| elif row.LCL6 == row. LCL7 == row.LCL8 == '0/0': | |||
| mendelian = mendelian + ':Ref' | |||
| elif pd.isnull(row.TRIO6) == True: | |||
| mendelian = mendelian + ':unVBT' | |||
| else: | |||
| mendelian = mendelian + ':' + row.TRIO6.split('=')[1] | |||
| # not count into family | |||
| if (row.LCL5 == './.' or row.LCL5 == '0/0') and (row.LCL6 == './.' or row.LCL6 == '0/0') and (row.LCL7 == './.' or row.LCL7 == '0/0') and (row.LCL8 == './.' or row.LCL8 == '0/0'): | |||
| mendelian_count = "no" | |||
| else: | |||
| mendelian_count = "yes" | |||
| outline = row.CHROM + '\t' + str(row.POS) + '\t' + row.REF + '\t' + row.ALT + '\t' + row.LCL5 + '\t' + row.LCL6 + '\t' + row.LCL7 + '\t' + row.LCL8 + '\t' + str(row.TRIO5) + '\t' + str(row.TRIO6) + '\t' + str(mendelian) + '\t' + str(mendelian_count) + '\t' + str(sister_count) + '\n' | |||
| family_file.write(outline) | |||
+ 109
- 0
codescripts/oneClass.py
View File
| @@ -0,0 +1,109 @@ | |||
| # import modules | |||
| import numpy as np | |||
| import pandas as pd | |||
| from sklearn import svm | |||
| from sklearn import preprocessing | |||
| import sys, argparse, os | |||
| from vcf2bed import position_to_bed,padding_region | |||
| parser = argparse.ArgumentParser(description="this script is to preform one calss svm on each chromosome") | |||
| parser.add_argument('-train', '--trainDataset', type=str, help='training dataset generated from extracting vcf information part, with mutaitons supported by callsets', required=True) | |||
| parser.add_argument('-test', '--testDataset', type=str, help='testing dataset generated from extracting vcf information part, with mutaitons not called by all callsets', required=True) | |||
| parser.add_argument('-name', '--sampleName', type=str, help='sample name for output file name', required=True) | |||
| args = parser.parse_args() | |||
| # Rename input: | |||
| train_input = args.trainDataset | |||
| test_input = args.testDataset | |||
| sample_name = args.sampleName | |||
| # default columns, which will be included in the included in the calssifier | |||
| chromosome = ['chr1','chr2','chr3','chr4','chr5','chr6','chr7','chr8','chr9','chr10','chr11','chr12','chr13','chr14','chr15' ,'chr16','chr17','chr18','chr19','chr20','chr21','chr22','chrX','chrY'] | |||
| feature_heter_cols = ['AltDP','BaseQRankSum','DB','DP','FS','GQ','MQ','MQRankSum','QD','ReadPosRankSum','RefDP','SOR','af'] | |||
| feature_homo_cols = ['AltDP','DB','DP','FS','GQ','MQ','QD','RefDP','SOR','af'] | |||
| # import datasets sepearate the records with or without BaseQRankSum annotation, etc. | |||
| def load_dat(dat_file_name): | |||
| dat = pd.read_table(dat_file_name) | |||
| dat['DB'] = dat['DB'].fillna(0) | |||
| dat = dat[dat['DP'] != 0] | |||
| dat['af'] = dat['AltDP']/(dat['AltDP'] + dat['RefDP']) | |||
| homo_rows = dat[dat['BaseQRankSum'].isnull()] | |||
| heter_rows = dat[dat['BaseQRankSum'].notnull()] | |||
| return homo_rows,heter_rows | |||
| train_homo,train_heter = load_dat(train_input) | |||
| test_homo,test_heter = load_dat(test_input) | |||
| clf = svm.OneClassSVM(nu=0.05,kernel='rbf', gamma='auto_deprecated',cache_size=500) | |||
| def prepare_dat(train_dat,test_dat,feature_cols,chromo): | |||
| chr_train = train_dat[train_dat['chromo'] == chromo] | |||
| chr_test = test_dat[test_dat['chromo'] == chromo] | |||
| train_dat = chr_train.loc[:,feature_cols] | |||
| test_dat = chr_test.loc[:,feature_cols] | |||
| train_dat_scaled = preprocessing.scale(train_dat) | |||
| test_dat_scaled = preprocessing.scale(test_dat) | |||
| return chr_test,train_dat_scaled,test_dat_scaled | |||
| def oneclass(X_train,X_test,chr_test): | |||
| clf.fit(X_train) | |||
| y_pred_test = clf.predict(X_test) | |||
| test_true_dat = chr_test[y_pred_test == 1] | |||
| test_false_dat = chr_test[y_pred_test == -1] | |||
| return test_true_dat,test_false_dat | |||
| predicted_true = pd.DataFrame(columns=train_homo.columns) | |||
| predicted_false = pd.DataFrame(columns=train_homo.columns) | |||
| for chromo in chromosome: | |||
| # homo datasets | |||
| chr_test_homo,X_train_homo,X_test_homo = prepare_dat(train_homo,test_homo,feature_homo_cols,chromo) | |||
| test_true_homo,test_false_homo = oneclass(X_train_homo,X_test_homo,chr_test_homo) | |||
| predicted_true = predicted_true.append(test_true_homo) | |||
| predicted_false = predicted_false.append(test_false_homo) | |||
| # heter datasets | |||
| chr_test_heter,X_train_heter,X_test_heter = prepare_dat(train_heter,test_heter,feature_heter_cols,chromo) | |||
| test_true_heter,test_false_heter = oneclass(X_train_heter,X_test_heter,chr_test_heter) | |||
| predicted_true = predicted_true.append(test_true_heter) | |||
| predicted_false = predicted_false.append(test_false_heter) | |||
| predicted_true_filename = sample_name + '_predicted_true.txt' | |||
| predicted_false_filename = sample_name + '_predicted_false.txt' | |||
| predicted_true.to_csv(predicted_true_filename,sep='\t',index=False) | |||
| predicted_false.to_csv(predicted_false_filename,sep='\t',index=False) | |||
| # output the bed file and padding bed region 50bp | |||
| predicted_true_bed_filename = sample_name + '_predicted_true.bed' | |||
| predicted_false_bed_filename = sample_name + '_predicted_false.bed' | |||
| padding_filename = sample_name + '_padding.bed' | |||
| predicted_true_bed = open(predicted_true_bed_filename,'w') | |||
| predicted_false_bed = open(predicted_false_bed_filename,'w') | |||
| padding = open(padding_filename,'w') | |||
| # | |||
| for index,row in predicted_false.iterrows(): | |||
| chromo,pos1,pos2 = position_to_bed(row['chromo'],row['pos'],row['ref'],row['alt']) | |||
| outline_pos = chromo + '\t' + str(pos1) + '\t' + str(pos2) + '\n' | |||
| predicted_false_bed.write(outline_pos) | |||
| chromo,pad_pos1,pad_pos2,pad_pos3,pad_pos4 = padding_region(chromo,pos1,pos2,50) | |||
| outline_pad_1 = chromo + '\t' + str(pad_pos1) + '\t' + str(pad_pos2) + '\n' | |||
| outline_pad_2 = chromo + '\t' + str(pad_pos3) + '\t' + str(pad_pos4) + '\n' | |||
| padding.write(outline_pad_1) | |||
| padding.write(outline_pad_2) | |||
| for index,row in predicted_true.iterrows(): | |||
| chromo,pos1,pos2 = position_to_bed(row['chromo'],row['pos'],row['ref'],row['alt']) | |||
| outline_pos = chromo + '\t' + str(pos1) + '\t' + str(pos2) + '\n' | |||
| predicted_true_bed.write(outline_pos) | |||
+ 144
- 0
codescripts/reformVCF.py
View File
| @@ -0,0 +1,144 @@ | |||
| # import modules | |||
| import sys, argparse, os | |||
| import fileinput | |||
| import re | |||
| parser = argparse.ArgumentParser(description="This script is to split samples in VCF files and rewrite to the right style") | |||
| parser.add_argument('-vcf', '--familyVCF', type=str, help='VCF with sister and mendelian infomation', required=True) | |||
| parser.add_argument('-name', '--familyName', type=str, help='Family name of the VCF file', required=True) | |||
| args = parser.parse_args() | |||
| # Rename input: | |||
| inputFile = args.familyVCF | |||
| family_name = args.familyName | |||
| # output filename | |||
| LCL5_name = family_name + '.LCL5.vcf' | |||
| LCL5file = open(LCL5_name,'w') | |||
| LCL6_name = family_name + '.LCL6.vcf' | |||
| LCL6file = open(LCL6_name,'w') | |||
| LCL7_name = family_name + '.LCL7.vcf' | |||
| LCL7file = open(LCL7_name,'w') | |||
| LCL8_name = family_name + '.LCL8.vcf' | |||
| LCL8file = open(LCL8_name,'w') | |||
| family_filename = family_name + '.vcf' | |||
| familyfile = open(family_filename,'w') | |||
| # default columns, which will be included in the included in the calssifier | |||
| vcfheader = '''##fileformat=VCFv4.2 | |||
| ##FILTER=<ID=PASS,Description="the same genotype between twin sister and mendelian consistent in 578 and 678"> | |||
| ##FORMAT=<ID=GT,Number=1,Type=String,Description="Genotype"> | |||
| ##FORMAT=<ID=TWINS,Number=0,Type=Flag,Description="0 for sister consistent, 1 for sister inconsistent"> | |||
| ##FORMAT=<ID=TRIO5,Number=0,Type=Flag,Description="0 for trio consistent, 1 for trio inconsistent"> | |||
| ##FORMAT=<ID=TRIO6,Number=0,Type=Flag,Description="0 for trio consistent, 1 for trio inconsistent"> | |||
| ##contig=<ID=chr1,length=248956422> | |||
| ##contig=<ID=chr2,length=242193529> | |||
| ##contig=<ID=chr3,length=198295559> | |||
| ##contig=<ID=chr4,length=190214555> | |||
| ##contig=<ID=chr5,length=181538259> | |||
| ##contig=<ID=chr6,length=170805979> | |||
| ##contig=<ID=chr7,length=159345973> | |||
| ##contig=<ID=chr8,length=145138636> | |||
| ##contig=<ID=chr9,length=138394717> | |||
| ##contig=<ID=chr10,length=133797422> | |||
| ##contig=<ID=chr11,length=135086622> | |||
| ##contig=<ID=chr12,length=133275309> | |||
| ##contig=<ID=chr13,length=114364328> | |||
| ##contig=<ID=chr14,length=107043718> | |||
| ##contig=<ID=chr15,length=101991189> | |||
| ##contig=<ID=chr16,length=90338345> | |||
| ##contig=<ID=chr17,length=83257441> | |||
| ##contig=<ID=chr18,length=80373285> | |||
| ##contig=<ID=chr19,length=58617616> | |||
| ##contig=<ID=chr20,length=64444167> | |||
| ##contig=<ID=chr21,length=46709983> | |||
| ##contig=<ID=chr22,length=50818468> | |||
| ##contig=<ID=chrX,length=156040895> | |||
| ''' | |||
| # write VCF | |||
| LCL5colname = '#CHROM\tPOS\tID\tREF\tALT\tQUAL\tFILTER\tINFO\tFORMAT\t'+family_name+'_LCL5'+'\n' | |||
| LCL5file.write(vcfheader) | |||
| LCL5file.write(LCL5colname) | |||
| LCL6colname = '#CHROM\tPOS\tID\tREF\tALT\tQUAL\tFILTER\tINFO\tFORMAT\t'+family_name+'_LCL6'+'\n' | |||
| LCL6file.write(vcfheader) | |||
| LCL6file.write(LCL6colname) | |||
| LCL7colname = '#CHROM\tPOS\tID\tREF\tALT\tQUAL\tFILTER\tINFO\tFORMAT\t'+family_name+'_LCL7'+'\n' | |||
| LCL7file.write(vcfheader) | |||
| LCL7file.write(LCL7colname) | |||
| LCL8colname = '#CHROM\tPOS\tID\tREF\tALT\tQUAL\tFILTER\tINFO\tFORMAT\t'+family_name+'_LCL8'+'\n' | |||
| LCL8file.write(vcfheader) | |||
| LCL8file.write(LCL8colname) | |||
| familycolname = '#CHROM\tPOS\tID\tREF\tALT\tQUAL\tFILTER\tINFO\tFORMAT\t'+'LCL5\t'+'LCL6\t'+'LCL7\t'+'LCL8'+'\n' | |||
| familyfile.write(vcfheader) | |||
| familyfile.write(familycolname) | |||
| # reform VCF | |||
| def process(oneLine): | |||
| line = oneLine.rstrip() | |||
| strings = line.strip().split('\t') | |||
| # replace . | |||
| # LCL6 uniq | |||
| if strings[11] == '.': | |||
| strings[11] = '0/0' | |||
| strings[9] = strings[12] | |||
| strings[10] = strings[13] | |||
| else: | |||
| pass | |||
| # LCL5 uniq | |||
| if strings[14] == '.': | |||
| strings[14] = '0/0' | |||
| strings[12] = strings[9] | |||
| strings[13] = strings[10] | |||
| else: | |||
| pass | |||
| # sister | |||
| if strings[11] == strings[14]: | |||
| add_format = ":1" | |||
| else: | |||
| add_format = ":0" | |||
| # trioLCL5 | |||
| if strings[15] == 'MD=1': | |||
| add_format = add_format + ":1" | |||
| else: | |||
| add_format = add_format + ":0" | |||
| # trioLCL6 | |||
| if strings[7] == 'MD=1': | |||
| add_format = add_format + ":1" | |||
| else: | |||
| add_format = add_format + ":0" | |||
| # filter | |||
| if (strings[11] == strings[14]) and (strings[15] == 'MD=1') and (strings[7] == 'MD=1'): | |||
| strings[6] = 'PASS' | |||
| else: | |||
| strings[6] = '.' | |||
| # output LCL5 | |||
| LCL5outLine = strings[0]+'\t'+strings[1]+'\t'+strings[2]+'\t'+strings[3]+'\t'+strings[4]+'\t'+'.'+'\t'+strings[6]+'\t'+ '.' +'\t'+ 'GT:TWINS:TRIO5:TRIO6' + '\t' + strings[14] + add_format + '\n' | |||
| LCL5file.write(LCL5outLine) | |||
| # output LCL6 | |||
| LCL6outLine = strings[0]+'\t'+strings[1]+'\t'+strings[2]+'\t'+strings[3]+'\t'+strings[4]+'\t'+'.'+'\t'+strings[6]+'\t'+ '.' +'\t'+ 'GT:TWINS:TRIO5:TRIO6' + '\t' + strings[11] + add_format + '\n' | |||
| LCL6file.write(LCL6outLine) | |||
| # output LCL7 | |||
| LCL7outLine = strings[0]+'\t'+strings[1]+'\t'+strings[2]+'\t'+strings[3]+'\t'+strings[4]+'\t'+'.'+'\t'+strings[6]+'\t'+ '.' +'\t'+ 'GT:TWINS:TRIO5:TRIO6' + '\t' + strings[10] + add_format + '\n' | |||
| LCL7file.write(LCL7outLine) | |||
| # output LCL8 | |||
| LCL8outLine = strings[0]+'\t'+strings[1]+'\t'+strings[2]+'\t'+strings[3]+'\t'+strings[4]+'\t'+'.'+'\t'+strings[6]+'\t'+ '.' +'\t'+ 'GT:TWINS:TRIO5:TRIO6' + '\t' + strings[9] + add_format + '\n' | |||
| LCL8file.write(LCL8outLine) | |||
| # output family | |||
| familyoutLine = strings[0]+'\t'+strings[1]+'\t'+strings[2]+'\t'+strings[3]+'\t'+strings[4]+'\t'+ '.'+'\t'+strings[6]+'\t'+ '.' +'\t'+ 'GT:TWINS:TRIO5:TRIO6' + '\t' + strings[14] + add_format +'\t' + strings[11] + add_format + '\t' + strings[10] + add_format +'\t' + strings[9] + add_format + '\n' | |||
| familyfile.write(familyoutLine) | |||
| for line in fileinput.input(inputFile): | |||
| m = re.match('^\#',line) | |||
| if m is not None: | |||
| pass | |||
| else: | |||
| process(line) | |||
+ 199
- 0
codescripts/replicates_consensus.py
View File
| @@ -0,0 +1,199 @@ | |||
| from __future__ import division | |||
| from glob import glob | |||
| import sys, argparse, os | |||
| import fileinput | |||
| import re | |||
| import pandas as pd | |||
| from operator import itemgetter | |||
| from collections import Counter | |||
| from itertools import islice | |||
| from numpy import * | |||
| import statistics | |||
| # input arguments | |||
| parser = argparse.ArgumentParser(description="this script is to merge mendelian and vcfinfo, and extract high_confidence_calls") | |||
| parser.add_argument('-prefix', '--prefix', type=str, help='prefix of output file', required=True) | |||
| parser.add_argument('-vcf', '--vcf', type=str, help='merged multiple sample vcf', required=True) | |||
| args = parser.parse_args() | |||
| prefix = args.prefix | |||
| vcf = args.vcf | |||
| # input files | |||
| vcf_dat = pd.read_table(vcf) | |||
| # all info | |||
| all_file_name = prefix + "_all_summary.txt" | |||
| all_sample_outfile = open(all_file_name,'w') | |||
| all_info_col = 'CHROM\tPOS\tREF\tALT\tLCL5_consensus_calls\tLCL5_detect_number\tLCL5_same_diff\tLCL6_consensus_calls\tLCL6_detect_number\tLCl6_same_diff\tLCL7_consensus_calls\tLCL7_detect_number\tLCL7_same_diff\tLCL8_consensus_calls\tLCL8_detect_number\tLCL8_same_diff\n' | |||
| all_sample_outfile.write(all_info_col) | |||
| # filtered info | |||
| vcf_header = '''##fileformat=VCFv4.2 | |||
| ##fileDate=20200501 | |||
| ##source=high_confidence_calls_intergration(choppy app) | |||
| ##reference=GRCh38.d1.vd1 | |||
| ##INFO=<ID=VOTED,Number=1,Type=Integer,Description="Number mendelian consisitent votes"> | |||
| ##FORMAT=<ID=GT,Number=1,Type=String,Description="Genotype"> | |||
| ##contig=<ID=chr1,length=248956422> | |||
| ##contig=<ID=chr2,length=242193529> | |||
| ##contig=<ID=chr3,length=198295559> | |||
| ##contig=<ID=chr4,length=190214555> | |||
| ##contig=<ID=chr5,length=181538259> | |||
| ##contig=<ID=chr6,length=170805979> | |||
| ##contig=<ID=chr7,length=159345973> | |||
| ##contig=<ID=chr8,length=145138636> | |||
| ##contig=<ID=chr9,length=138394717> | |||
| ##contig=<ID=chr10,length=133797422> | |||
| ##contig=<ID=chr11,length=135086622> | |||
| ##contig=<ID=chr12,length=133275309> | |||
| ##contig=<ID=chr13,length=114364328> | |||
| ##contig=<ID=chr14,length=107043718> | |||
| ##contig=<ID=chr15,length=101991189> | |||
| ##contig=<ID=chr16,length=90338345> | |||
| ##contig=<ID=chr17,length=83257441> | |||
| ##contig=<ID=chr18,length=80373285> | |||
| ##contig=<ID=chr19,length=58617616> | |||
| ##contig=<ID=chr20,length=64444167> | |||
| ##contig=<ID=chr21,length=46709983> | |||
| ##contig=<ID=chr22,length=50818468> | |||
| ##contig=<ID=chrX,length=156040895> | |||
| ''' | |||
| consensus_file_name = prefix + "_consensus.vcf" | |||
| consensus_outfile = open(consensus_file_name,'w') | |||
| consensus_col = '#CHROM\tPOS\tID\tREF\tALT\tQUAL\tFILTER\tINFO\tFORMAT\tLCL5_consensus_calls\tLCL6_consensus_calls\tLCL7_consensus_calls\tLCL8_consensus_calls\n' | |||
| consensus_outfile.write(vcf_header) | |||
| consensus_outfile.write(consensus_col) | |||
| # function | |||
| def decide_by_rep(vcf_list): | |||
| consensus_rep = '' | |||
| gt = [x.split(':')[0] for x in vcf_list] | |||
| gt_num_dict = Counter(gt) | |||
| highest_gt = gt_num_dict.most_common(1) | |||
| candidate_gt = highest_gt[0][0] | |||
| freq_gt = highest_gt[0][1] | |||
| if freq_gt >= 2: | |||
| consensus_rep = candidate_gt | |||
| else: | |||
| consensus_rep = 'inconGT' | |||
| return consensus_rep | |||
| def consensus_call(vcf_info_list): | |||
| consensus_call = '.' | |||
| detect_number = '.' | |||
| same_diff = '.' | |||
| # pcr | |||
| SEQ2000 = decide_by_rep(vcf_info_list[0:3]) | |||
| XTen_ARD = decide_by_rep(vcf_info_list[18:21]) | |||
| XTen_NVG = decide_by_rep(vcf_info_list[21:24]) | |||
| XTen_WUX = decide_by_rep(vcf_info_list[24:27]) | |||
| Nova_WUX = decide_by_rep(vcf_info_list[15:18]) | |||
| pcr_sequence_site = [SEQ2000,XTen_ARD,XTen_NVG,XTen_WUX,Nova_WUX] | |||
| pcr_sequence_dict = Counter(pcr_sequence_site) | |||
| pcr_highest_sequence = pcr_sequence_dict.most_common(1) | |||
| pcr_candidate_sequence = pcr_highest_sequence[0][0] | |||
| pcr_freq_sequence = pcr_highest_sequence[0][1] | |||
| if pcr_freq_sequence > 3: | |||
| pcr_consensus = pcr_candidate_sequence | |||
| else: | |||
| pcr_consensus = 'inconSequenceSite' | |||
| # pcr-free | |||
| T7_WGE = decide_by_rep(vcf_info_list[3:6]) | |||
| Nova_ARD_1 = decide_by_rep(vcf_info_list[6:9]) | |||
| Nova_ARD_2 = decide_by_rep(vcf_info_list[9:12]) | |||
| Nova_BRG = decide_by_rep(vcf_info_list[12:15]) | |||
| sequence_site = [T7_WGE,Nova_ARD_1,Nova_ARD_2,Nova_BRG] | |||
| sequence_dict = Counter(sequence_site) | |||
| highest_sequence = sequence_dict.most_common(1) | |||
| candidate_sequence = highest_sequence[0][0] | |||
| freq_sequence = highest_sequence[0][1] | |||
| if freq_sequence > 2: | |||
| pcr_free_consensus = candidate_sequence | |||
| else: | |||
| pcr_free_consensus = 'inconSequenceSite' | |||
| gt = [x.split(':')[0] for x in vcf_info_list] | |||
| gt = [x.replace('./.','.') for x in gt] | |||
| detected_num = 27 - gt.count('.') | |||
| gt_remain = [e for e in gt if e not in {'.'}] | |||
| gt_set = set(gt_remain) | |||
| if len(gt_set) == 1: | |||
| same_diff = 'same' | |||
| else: | |||
| same_diff = 'diff' | |||
| tag = ['inconGT','inconSequenceSite'] | |||
| if (pcr_consensus == pcr_free_consensus) and (pcr_consensus not in tag): | |||
| consensus_call = pcr_consensus | |||
| else: | |||
| consensus_call = 'notConsensus' | |||
| return consensus_call, detected_num, same_diff | |||
| for row in vcf_dat.itertuples(): | |||
| lcl5_list = [row.Quartet_DNA_BGI_SEQ2000_BGI_LCL5_1_20180518,row.Quartet_DNA_BGI_SEQ2000_BGI_LCL5_2_20180530,row.Quartet_DNA_BGI_SEQ2000_BGI_LCL5_3_20180530, \ | |||
| row.Quartet_DNA_BGI_T7_WGE_LCL5_1_20191105,row.Quartet_DNA_BGI_T7_WGE_LCL5_2_20191105,row.Quartet_DNA_BGI_T7_WGE_LCL5_3_20191105, \ | |||
| row.Quartet_DNA_ILM_Nova_ARD_LCL5_1_20181108,row.Quartet_DNA_ILM_Nova_ARD_LCL5_2_20181108,row.Quartet_DNA_ILM_Nova_ARD_LCL5_3_20181108, \ | |||
| row.Quartet_DNA_ILM_Nova_ARD_LCL5_4_20190111,row.Quartet_DNA_ILM_Nova_ARD_LCL5_5_20190111,row.Quartet_DNA_ILM_Nova_ARD_LCL5_6_20190111, \ | |||
| row.Quartet_DNA_ILM_Nova_BRG_LCL5_1_20180930,row.Quartet_DNA_ILM_Nova_BRG_LCL5_2_20180930,row.Quartet_DNA_ILM_Nova_BRG_LCL5_3_20180930, \ | |||
| row.Quartet_DNA_ILM_Nova_WUX_LCL5_1_20190917,row.Quartet_DNA_ILM_Nova_WUX_LCL5_2_20190917,row.Quartet_DNA_ILM_Nova_WUX_LCL5_3_20190917, \ | |||
| row.Quartet_DNA_ILM_XTen_ARD_LCL5_1_20170403,row.Quartet_DNA_ILM_XTen_ARD_LCL5_2_20170403,row.Quartet_DNA_ILM_XTen_ARD_LCL5_3_20170403, \ | |||
| row.Quartet_DNA_ILM_XTen_NVG_LCL5_1_20170329,row.Quartet_DNA_ILM_XTen_NVG_LCL5_2_20170329,row.Quartet_DNA_ILM_XTen_NVG_LCL5_3_20170329, \ | |||
| row.Quartet_DNA_ILM_XTen_WUX_LCL5_1_20170216,row.Quartet_DNA_ILM_XTen_WUX_LCL5_2_20170216,row.Quartet_DNA_ILM_XTen_WUX_LCL5_3_20170216] | |||
| lcl6_list = [row.Quartet_DNA_BGI_SEQ2000_BGI_LCL6_1_20180518,row.Quartet_DNA_BGI_SEQ2000_BGI_LCL6_2_20180530,row.Quartet_DNA_BGI_SEQ2000_BGI_LCL6_3_20180530, \ | |||
| row.Quartet_DNA_BGI_T7_WGE_LCL6_1_20191105,row.Quartet_DNA_BGI_T7_WGE_LCL6_2_20191105,row.Quartet_DNA_BGI_T7_WGE_LCL6_3_20191105, \ | |||
| row.Quartet_DNA_ILM_Nova_ARD_LCL6_1_20181108,row.Quartet_DNA_ILM_Nova_ARD_LCL6_2_20181108,row.Quartet_DNA_ILM_Nova_ARD_LCL6_3_20181108, \ | |||
| row.Quartet_DNA_ILM_Nova_ARD_LCL6_4_20190111,row.Quartet_DNA_ILM_Nova_ARD_LCL6_5_20190111,row.Quartet_DNA_ILM_Nova_ARD_LCL6_6_20190111, \ | |||
| row.Quartet_DNA_ILM_Nova_BRG_LCL6_1_20180930,row.Quartet_DNA_ILM_Nova_BRG_LCL6_2_20180930,row.Quartet_DNA_ILM_Nova_BRG_LCL6_3_20180930, \ | |||
| row.Quartet_DNA_ILM_Nova_WUX_LCL6_1_20190917,row.Quartet_DNA_ILM_Nova_WUX_LCL6_2_20190917,row.Quartet_DNA_ILM_Nova_WUX_LCL6_3_20190917, \ | |||
| row.Quartet_DNA_ILM_XTen_ARD_LCL6_1_20170403,row.Quartet_DNA_ILM_XTen_ARD_LCL6_2_20170403,row.Quartet_DNA_ILM_XTen_ARD_LCL6_3_20170403, \ | |||
| row.Quartet_DNA_ILM_XTen_NVG_LCL6_1_20170329,row.Quartet_DNA_ILM_XTen_NVG_LCL6_2_20170329,row.Quartet_DNA_ILM_XTen_NVG_LCL6_3_20170329, \ | |||
| row.Quartet_DNA_ILM_XTen_WUX_LCL6_1_20170216,row.Quartet_DNA_ILM_XTen_WUX_LCL6_2_20170216,row.Quartet_DNA_ILM_XTen_WUX_LCL6_3_20170216] | |||
| lcl7_list = [row.Quartet_DNA_BGI_SEQ2000_BGI_LCL7_1_20180518,row.Quartet_DNA_BGI_SEQ2000_BGI_LCL7_2_20180530,row.Quartet_DNA_BGI_SEQ2000_BGI_LCL7_3_20180530, \ | |||
| row.Quartet_DNA_BGI_T7_WGE_LCL7_1_20191105,row.Quartet_DNA_BGI_T7_WGE_LCL7_2_20191105,row.Quartet_DNA_BGI_T7_WGE_LCL7_3_20191105, \ | |||
| row.Quartet_DNA_ILM_Nova_ARD_LCL7_1_20181108,row.Quartet_DNA_ILM_Nova_ARD_LCL7_2_20181108,row.Quartet_DNA_ILM_Nova_ARD_LCL7_3_20181108, \ | |||
| row.Quartet_DNA_ILM_Nova_ARD_LCL7_4_20190111,row.Quartet_DNA_ILM_Nova_ARD_LCL7_5_20190111,row.Quartet_DNA_ILM_Nova_ARD_LCL7_6_20190111, \ | |||
| row.Quartet_DNA_ILM_Nova_BRG_LCL7_1_20180930,row.Quartet_DNA_ILM_Nova_BRG_LCL7_2_20180930,row.Quartet_DNA_ILM_Nova_BRG_LCL7_3_20180930, \ | |||
| row.Quartet_DNA_ILM_Nova_WUX_LCL7_1_20190917,row.Quartet_DNA_ILM_Nova_WUX_LCL7_2_20190917,row.Quartet_DNA_ILM_Nova_WUX_LCL7_3_20190917, \ | |||
| row.Quartet_DNA_ILM_XTen_ARD_LCL7_1_20170403,row.Quartet_DNA_ILM_XTen_ARD_LCL7_2_20170403,row.Quartet_DNA_ILM_XTen_ARD_LCL7_3_20170403, \ | |||
| row.Quartet_DNA_ILM_XTen_NVG_LCL7_1_20170329,row.Quartet_DNA_ILM_XTen_NVG_LCL7_2_20170329,row.Quartet_DNA_ILM_XTen_NVG_LCL7_3_20170329, \ | |||
| row.Quartet_DNA_ILM_XTen_WUX_LCL7_1_20170216,row.Quartet_DNA_ILM_XTen_WUX_LCL7_2_20170216,row.Quartet_DNA_ILM_XTen_WUX_LCL7_3_20170216] | |||
| lcl8_list = [row.Quartet_DNA_BGI_SEQ2000_BGI_LCL8_1_20180518,row.Quartet_DNA_BGI_SEQ2000_BGI_LCL8_2_20180530,row.Quartet_DNA_BGI_SEQ2000_BGI_LCL8_3_20180530, \ | |||
| row.Quartet_DNA_BGI_T7_WGE_LCL8_1_20191105,row.Quartet_DNA_BGI_T7_WGE_LCL8_2_20191105,row.Quartet_DNA_BGI_T7_WGE_LCL8_3_20191105, \ | |||
| row.Quartet_DNA_ILM_Nova_ARD_LCL8_1_20181108,row.Quartet_DNA_ILM_Nova_ARD_LCL8_2_20181108,row.Quartet_DNA_ILM_Nova_ARD_LCL8_3_20181108, \ | |||
| row.Quartet_DNA_ILM_Nova_ARD_LCL8_4_20190111,row.Quartet_DNA_ILM_Nova_ARD_LCL8_5_20190111,row.Quartet_DNA_ILM_Nova_ARD_LCL8_6_20190111, \ | |||
| row.Quartet_DNA_ILM_Nova_BRG_LCL8_1_20180930,row.Quartet_DNA_ILM_Nova_BRG_LCL8_2_20180930,row.Quartet_DNA_ILM_Nova_BRG_LCL8_3_20180930, \ | |||
| row.Quartet_DNA_ILM_Nova_WUX_LCL8_1_20190917,row.Quartet_DNA_ILM_Nova_WUX_LCL8_2_20190917,row.Quartet_DNA_ILM_Nova_WUX_LCL8_3_20190917, \ | |||
| row.Quartet_DNA_ILM_XTen_ARD_LCL8_1_20170403,row.Quartet_DNA_ILM_XTen_ARD_LCL8_2_20170403,row.Quartet_DNA_ILM_XTen_ARD_LCL8_3_20170403, \ | |||
| row.Quartet_DNA_ILM_XTen_NVG_LCL8_1_20170329,row.Quartet_DNA_ILM_XTen_NVG_LCL8_2_20170329,row.Quartet_DNA_ILM_XTen_NVG_LCL8_3_20170329, \ | |||
| row.Quartet_DNA_ILM_XTen_WUX_LCL8_1_20170216,row.Quartet_DNA_ILM_XTen_WUX_LCL8_2_20170216,row.Quartet_DNA_ILM_XTen_WUX_LCL8_3_20170216] | |||
| # LCL5 | |||
| LCL5_consensus_call, LCL5_detected_num, LCL5_same_diff = consensus_call(lcl5_list) | |||
| # LCL6 | |||
| LCL6_consensus_call, LCL6_detected_num, LCL6_same_diff = consensus_call(lcl6_list) | |||
| # LCL7 | |||
| LCL7_consensus_call, LCL7_detected_num, LCL7_same_diff = consensus_call(lcl7_list) | |||
| # LCL8 | |||
| LCL8_consensus_call, LCL8_detected_num, LCL8_same_diff = consensus_call(lcl8_list) | |||
| # all data | |||
| all_output = row._1 + '\t' + str(row.POS) + '\t' + row.REF + '\t' + row.ALT + '\t' + LCL5_consensus_call + '\t' + str(LCL5_detected_num) + '\t' + LCL5_same_diff + '\t' +\ | |||
| LCL6_consensus_call + '\t' + str(LCL6_detected_num) + '\t' + LCL6_same_diff + '\t' +\ | |||
| LCL7_consensus_call + '\t' + str(LCL7_detected_num) + '\t' + LCL7_same_diff + '\t' +\ | |||
| LCL8_consensus_call + '\t' + str(LCL8_detected_num) + '\t' + LCL8_same_diff + '\n' | |||
| all_sample_outfile.write(all_output) | |||
| #consensus vcf | |||
| one_position = [LCL5_consensus_call,LCL6_consensus_call,LCL7_consensus_call,LCL8_consensus_call] | |||
| if ('notConsensus' in one_position) or (((len(set(one_position)) == 1) and ('./.' in set(one_position))) or ((len(set(one_position)) == 1) and ('0/0' in set(one_position))) or ((len(set(one_position)) == 2) and ('0/0' in set(one_position) and ('./.' in set(one_position))))): | |||
| pass | |||
| else: | |||
| consensus_output = row._1 + '\t' + str(row.POS) + '\t' + '.' + '\t' + row.REF + '\t' + row.ALT + '\t' + '.' + '\t' + '.' + '\t' +'.' + '\t' + 'GT' + '\t' + LCL5_consensus_call + '\t' + LCL6_consensus_call + '\t' + LCL7_consensus_call + '\t' + LCL8_consensus_call +'\n' | |||
| consensus_outfile.write(consensus_output) | |||
+ 36
- 0
codescripts/vcf2bed.py
View File
| @@ -0,0 +1,36 @@ | |||
| import re | |||
| def position_to_bed(chromo,pos,ref,alt): | |||
| # snv | |||
| # Start cooridinate BED = start coordinate VCF - 1 | |||
| # End cooridinate BED = start coordinate VCF | |||
| if len(ref) == 1 and len(alt) == 1: | |||
| StartPos = int(pos) -1 | |||
| EndPos = int(pos) | |||
| # deletions | |||
| # Start cooridinate BED = start coordinate VCF - 1 | |||
| # End cooridinate BED = start coordinate VCF + (reference length - alternate length) | |||
| elif len(ref) > 1 and len(alt) == 1: | |||
| StartPos = int(pos) - 1 | |||
| EndPos = int(pos) + (len(ref) - 1) | |||
| #insertions | |||
| # For insertions: | |||
| # Start cooridinate BED = start coordinate VCF - 1 | |||
| # End cooridinate BED = start coordinate VCF + (alternate length - reference length) | |||
| else: | |||
| StartPos = int(pos) - 1 | |||
| EndPos = int(pos) + (len(alt) - 1) | |||
| return chromo,StartPos,EndPos | |||
| def padding_region(chromo,pos1,pos2,padding): | |||
| StartPos1 = pos1 - padding | |||
| EndPos1 = pos1 | |||
| StartPos2 = pos2 | |||
| EndPos2 = pos2 + padding | |||
| return chromo,StartPos1,EndPos1,StartPos2,EndPos2 | |||
+ 295
- 0
codescripts/voted_by_vcfinfo_mendelianinfo.py
View File
| @@ -0,0 +1,295 @@ | |||
| from __future__ import division | |||
| from glob import glob | |||
| import sys, argparse, os | |||
| import fileinput | |||
| import re | |||
| import pandas as pd | |||
| from operator import itemgetter | |||
| from collections import Counter | |||
| from itertools import islice | |||
| from numpy import * | |||
| import statistics | |||
| # input arguments | |||
| parser = argparse.ArgumentParser(description="this script is to merge mendelian and vcfinfo, and extract high_confidence_calls") | |||
| parser.add_argument('-folder', '--folder', type=str, help='directory that holds all the mendelian info', required=True) | |||
| parser.add_argument('-vcf', '--vcf', type=str, help='merged multiple sample vcf', required=True) | |||
| args = parser.parse_args() | |||
| folder = args.folder | |||
| vcf = args.vcf | |||
| # input files | |||
| folder = folder + '/*.txt' | |||
| filenames = glob(folder) | |||
| dataframes = [] | |||
| for filename in filenames: | |||
| dataframes.append(pd.read_table(filename,header=None)) | |||
| dfs = [df.set_index([0, 1]) for df in dataframes] | |||
| merged_mendelian = pd.concat(dfs, axis=1).reset_index() | |||
| family_name = [i.split('/')[-1].replace('.txt','') for i in filenames] | |||
| columns = ['CHROM','POS'] + family_name | |||
| merged_mendelian.columns = columns | |||
| vcf_dat = pd.read_table(vcf) | |||
| merged_df = pd.merge(merged_mendelian, vcf_dat, how='outer', left_on=['CHROM','POS'], right_on = ['#CHROM','POS']) | |||
| merged_df = merged_df.fillna('nan') | |||
| vcf_header = '''##fileformat=VCFv4.2 | |||
| ##fileDate=20200501 | |||
| ##source=high_confidence_calls_intergration(choppy app) | |||
| ##reference=GRCh38.d1.vd1 | |||
| ##INFO=<ID=VOTED,Number=1,Type=Integer,Description="Number mendelian consisitent votes"> | |||
| ##FORMAT=<ID=GT,Number=1,Type=String,Description="Genotype"> | |||
| ##FORMAT=<ID=DP,Number=1,Type=Integer,Description="Sum depth of all samples"> | |||
| ##FORMAT=<ID=ALT,Number=1,Type=Integer,Description="Sum alternative depth of all samples"> | |||
| ##contig=<ID=chr1,length=248956422> | |||
| ##contig=<ID=chr2,length=242193529> | |||
| ##contig=<ID=chr3,length=198295559> | |||
| ##contig=<ID=chr4,length=190214555> | |||
| ##contig=<ID=chr5,length=181538259> | |||
| ##contig=<ID=chr6,length=170805979> | |||
| ##contig=<ID=chr7,length=159345973> | |||
| ##contig=<ID=chr8,length=145138636> | |||
| ##contig=<ID=chr9,length=138394717> | |||
| ##contig=<ID=chr10,length=133797422> | |||
| ##contig=<ID=chr11,length=135086622> | |||
| ##contig=<ID=chr12,length=133275309> | |||
| ##contig=<ID=chr13,length=114364328> | |||
| ##contig=<ID=chr14,length=107043718> | |||
| ##contig=<ID=chr15,length=101991189> | |||
| ##contig=<ID=chr16,length=90338345> | |||
| ##contig=<ID=chr17,length=83257441> | |||
| ##contig=<ID=chr18,length=80373285> | |||
| ##contig=<ID=chr19,length=58617616> | |||
| ##contig=<ID=chr20,length=64444167> | |||
| ##contig=<ID=chr21,length=46709983> | |||
| ##contig=<ID=chr22,length=50818468> | |||
| ##contig=<ID=chrX,length=156040895> | |||
| ''' | |||
| # output files | |||
| benchmark_LCL5 = open('LCL5_voted.vcf','w') | |||
| benchmark_LCL6 = open('LCL6_voted.vcf','w') | |||
| benchmark_LCL7 = open('LCL7_voted.vcf','w') | |||
| benchmark_LCL8 = open('LCL8_voted.vcf','w') | |||
| all_sample_outfile = open('all_sample_information.txt','w') | |||
| # write VCF | |||
| LCL5_col = '#CHROM\tPOS\tID\tREF\tALT\tQUAL\tFILTER\tINFO\tFORMAT\tLCL5_benchmark_calls\n' | |||
| LCL6_col = '#CHROM\tPOS\tID\tREF\tALT\tQUAL\tFILTER\tINFO\tFORMAT\tLCL6_benchmark_calls\n' | |||
| LCL7_col = '#CHROM\tPOS\tID\tREF\tALT\tQUAL\tFILTER\tINFO\tFORMAT\tLCL7_benchmark_calls\n' | |||
| LCL8_col = '#CHROM\tPOS\tID\tREF\tALT\tQUAL\tFILTER\tINFO\tFORMAT\tLCL8_benchmark_calls\n' | |||
| benchmark_LCL5.write(vcf_header) | |||
| benchmark_LCL5.write(LCL5_col) | |||
| benchmark_LCL6.write(vcf_header) | |||
| benchmark_LCL6.write(LCL6_col) | |||
| benchmark_LCL7.write(vcf_header) | |||
| benchmark_LCL7.write(LCL7_col) | |||
| benchmark_LCL8.write(vcf_header) | |||
| benchmark_LCL8.write(LCL8_col) | |||
| # all info | |||
| all_info_col = 'CHROM\tPOS\tLCL5_pcr_consensus\tLCL5_pcr_free_consensus\tLCL5_mendelian_num\tLCL5_consensus_call\tLCL5_consensus_alt_seq\tLCL5_alt\tLCL5_dp\tLCL5_detected_num\tLCL6_pcr_consensus\tLCL6_pcr_free_consensus\tLCL6_mendelian_num\tLCL6_consensus_call\tLCL6_consensus_alt_seq\tLCL6_alt\tLCL6_dp\tLCL6_detected_num\tLCL7_pcr_consensus\tLCL7_pcr_free_consensus\tLCL7_mendelian_num\t LCL7_consensus_call\tLCL7_consensus_alt_seq\tLCL7_alt\tLCL7_dp\tLCL7_detected_num\tLCL8_pcr_consensus\tLCL8_pcr_free_consensus\tLCL8_mendelian_num\tLCL8_consensus_call\tLCL8_consensus_alt_seq\tLCL8_alt\tLCL8_dp\tLCL8_detected_num\n' | |||
| all_sample_outfile.write(all_info_col) | |||
| # function | |||
| def decide_by_rep(vcf_list,mendelian_list): | |||
| consensus_rep = '' | |||
| gt = [x.split(':')[0] for x in vcf_list] | |||
| # mendelian consistent? | |||
| mendelian_dict = Counter(mendelian_list) | |||
| highest_mendelian = mendelian_dict.most_common(1) | |||
| candidate_mendelian = highest_mendelian[0][0] | |||
| freq_mendelian = highest_mendelian[0][1] | |||
| if (candidate_mendelian == '1:1:1') and (freq_mendelian >= 2): | |||
| con_loc = [i for i in range(len(mendelian_list)) if mendelian_list[i] == '1:1:1'] | |||
| gt_con = itemgetter(*con_loc)(gt) | |||
| gt_num_dict = Counter(gt_con) | |||
| highest_gt = gt_num_dict.most_common(1) | |||
| candidate_gt = highest_gt[0][0] | |||
| freq_gt = highest_gt[0][1] | |||
| if (candidate_gt != './.') and (freq_gt >= 2): | |||
| consensus_rep = candidate_gt | |||
| elif (candidate_gt == './.') and (freq_gt >= 2): | |||
| consensus_rep = 'noGTInfo' | |||
| else: | |||
| consensus_rep = 'inconGT' | |||
| elif (candidate_mendelian == 'nan') and (freq_mendelian >= 2): | |||
| consensus_rep = 'noMenInfo' | |||
| else: | |||
| consensus_rep = 'inconMen' | |||
| return consensus_rep | |||
| def consensus_call(vcf_info_list,mendelian_list,alt_seq): | |||
| pcr_consensus = '.' | |||
| pcr_free_consensus = '.' | |||
| mendelian_num = '.' | |||
| consensus_call = '.' | |||
| consensus_alt_seq = '.' | |||
| # pcr | |||
| SEQ2000 = decide_by_rep(vcf_info_list[0:3],mendelian_list[0:3]) | |||
| XTen_ARD = decide_by_rep(vcf_info_list[18:21],mendelian_list[18:21]) | |||
| XTen_NVG = decide_by_rep(vcf_info_list[21:24],mendelian_list[21:24]) | |||
| XTen_WUX = decide_by_rep(vcf_info_list[24:27],mendelian_list[24:27]) | |||
| pcr_sequence_site = [SEQ2000,XTen_ARD,XTen_NVG,XTen_WUX] | |||
| pcr_sequence_dict = Counter(pcr_sequence_site) | |||
| pcr_highest_sequence = pcr_sequence_dict.most_common(1) | |||
| pcr_candidate_sequence = pcr_highest_sequence[0][0] | |||
| pcr_freq_sequence = pcr_highest_sequence[0][1] | |||
| if pcr_freq_sequence > 2: | |||
| pcr_consensus = pcr_candidate_sequence | |||
| else: | |||
| pcr_consensus = 'inconSequenceSite' | |||
| # pcr-free | |||
| T7_WGE = decide_by_rep(vcf_info_list[3:6],mendelian_list[3:6]) | |||
| Nova_ARD_1 = decide_by_rep(vcf_info_list[6:9],mendelian_list[6:9]) | |||
| Nova_ARD_2 = decide_by_rep(vcf_info_list[9:12],mendelian_list[9:12]) | |||
| Nova_BRG = decide_by_rep(vcf_info_list[12:15],mendelian_list[12:15]) | |||
| Nova_WUX = decide_by_rep(vcf_info_list[15:18],mendelian_list[15:18]) | |||
| sequence_site = [T7_WGE,Nova_ARD_1,Nova_ARD_2,Nova_BRG,Nova_WUX] | |||
| sequence_dict = Counter(sequence_site) | |||
| highest_sequence = sequence_dict.most_common(1) | |||
| candidate_sequence = highest_sequence[0][0] | |||
| freq_sequence = highest_sequence[0][1] | |||
| if freq_sequence > 3: | |||
| pcr_free_consensus = candidate_sequence | |||
| else: | |||
| pcr_free_consensus = 'inconSequenceSite' | |||
| # net alt, dp | |||
| # alt | |||
| AD = [x.split(':')[1] for x in vcf_info_list] | |||
| ALT = [x.split(',')[1] for x in AD] | |||
| ALT = [int(x) for x in ALT] | |||
| ALL_ALT = sum(ALT) | |||
| # dp | |||
| DP = [x.split(':')[2] for x in vcf_info_list] | |||
| DP = [int(x) for x in DP] | |||
| ALL_DP = sum(DP) | |||
| # detected number | |||
| gt = [x.split(':')[0] for x in vcf_info_list] | |||
| gt = [x.replace('0/0','.') for x in gt] | |||
| gt = [x.replace('./.','.') for x in gt] | |||
| detected_num = 27 - gt.count('.') | |||
| # decide consensus calls | |||
| tag = ['inconGT','noMenInfo','inconMen','inconSequenceSite','noGTInfo'] | |||
| if (pcr_consensus != '0/0') and (pcr_consensus == pcr_free_consensus) and (pcr_consensus not in tag): | |||
| consensus_call = pcr_consensus | |||
| gt = [x.split(':')[0] for x in vcf_info_list] | |||
| indices = [i for i, x in enumerate(gt) if x == consensus_call] | |||
| matched_mendelian = itemgetter(*indices)(mendelian_list) | |||
| mendelian_num = matched_mendelian.count('1:1:1') | |||
| # Delete multiple alternative genotype to necessary expression | |||
| alt_gt = alt_seq.split(',') | |||
| if len(alt_gt) > 1: | |||
| allele1 = consensus_call.split('/')[0] | |||
| allele2 = consensus_call.split('/')[1] | |||
| if allele1 == '0': | |||
| allele2_seq = alt_gt[int(allele2) - 1] | |||
| consensus_alt_seq = allele2_seq | |||
| consensus_call = '0/1' | |||
| else: | |||
| allele1_seq = alt_gt[int(allele1) - 1] | |||
| allele2_seq = alt_gt[int(allele2) - 1] | |||
| if int(allele1) > int(allele2): | |||
| consensus_alt_seq = allele2_seq + ',' + allele1_seq | |||
| consensus_call = '1/2' | |||
| elif int(allele1) < int(allele2): | |||
| consensus_alt_seq = allele1_seq + ',' + allele2_seq | |||
| consensus_call = '1/2' | |||
| else: | |||
| consensus_alt_seq = allele1_seq | |||
| consensus_call = '1/1' | |||
| else: | |||
| consensus_alt_seq = alt_seq | |||
| elif (pcr_consensus in tag) and (pcr_free_consensus in tag): | |||
| consensus_call = 'filtered' | |||
| elif ((pcr_consensus == './.') or (pcr_consensus in tag)) and ((pcr_free_consensus not in tag) and (pcr_free_consensus != './.')): | |||
| consensus_call = 'pcr-free-speicifc' | |||
| elif ((pcr_consensus != './.') or (pcr_consensus not in tag)) and ((pcr_free_consensus in tag) and (pcr_free_consensus == './.')): | |||
| consensus_call = 'pcr-speicifc' | |||
| elif (pcr_consensus == '0/0') and (pcr_free_consensus == '0/0'): | |||
| consensus_call = '0/0' | |||
| else: | |||
| consensus_call = 'filtered' | |||
| return pcr_consensus, pcr_free_consensus, mendelian_num, consensus_call, consensus_alt_seq, ALL_ALT, ALL_DP, detected_num | |||
| for row in merged_df.itertuples(): | |||
| mendelian_list = [row.Quartet_DNA_BGI_SEQ2000_BGI_1_20180518,row.Quartet_DNA_BGI_SEQ2000_BGI_2_20180530,row.Quartet_DNA_BGI_SEQ2000_BGI_3_20180530, \ | |||
| row.Quartet_DNA_BGI_T7_WGE_1_20191105,row.Quartet_DNA_BGI_T7_WGE_2_20191105,row.Quartet_DNA_BGI_T7_WGE_3_20191105, \ | |||
| row.Quartet_DNA_ILM_Nova_ARD_1_20181108,row.Quartet_DNA_ILM_Nova_ARD_2_20181108,row.Quartet_DNA_ILM_Nova_ARD_3_20181108, \ | |||
| row.Quartet_DNA_ILM_Nova_ARD_4_20190111,row.Quartet_DNA_ILM_Nova_ARD_5_20190111,row.Quartet_DNA_ILM_Nova_ARD_6_20190111, \ | |||
| row.Quartet_DNA_ILM_Nova_BRG_1_20180930,row.Quartet_DNA_ILM_Nova_BRG_2_20180930,row.Quartet_DNA_ILM_Nova_BRG_3_20180930, \ | |||
| row.Quartet_DNA_ILM_Nova_WUX_1_20190917,row.Quartet_DNA_ILM_Nova_WUX_2_20190917,row.Quartet_DNA_ILM_Nova_WUX_3_20190917, \ | |||
| row.Quartet_DNA_ILM_XTen_ARD_1_20170403,row.Quartet_DNA_ILM_XTen_ARD_2_20170403,row.Quartet_DNA_ILM_XTen_ARD_3_20170403, \ | |||
| row.Quartet_DNA_ILM_XTen_NVG_1_20170329,row.Quartet_DNA_ILM_XTen_NVG_2_20170329,row.Quartet_DNA_ILM_XTen_NVG_3_20170329, \ | |||
| row.Quartet_DNA_ILM_XTen_WUX_1_20170216,row.Quartet_DNA_ILM_XTen_WUX_2_20170216,row.Quartet_DNA_ILM_XTen_WUX_3_20170216] | |||
| lcl5_list = [row.Quartet_DNA_BGI_SEQ2000_BGI_LCL5_1_20180518,row.Quartet_DNA_BGI_SEQ2000_BGI_LCL5_2_20180530,row.Quartet_DNA_BGI_SEQ2000_BGI_LCL5_3_20180530, \ | |||
| row.Quartet_DNA_BGI_T7_WGE_LCL5_1_20191105,row.Quartet_DNA_BGI_T7_WGE_LCL5_2_20191105,row.Quartet_DNA_BGI_T7_WGE_LCL5_3_20191105, \ | |||
| row.Quartet_DNA_ILM_Nova_ARD_LCL5_1_20181108,row.Quartet_DNA_ILM_Nova_ARD_LCL5_2_20181108,row.Quartet_DNA_ILM_Nova_ARD_LCL5_3_20181108, \ | |||
| row.Quartet_DNA_ILM_Nova_ARD_LCL5_4_20190111,row.Quartet_DNA_ILM_Nova_ARD_LCL5_5_20190111,row.Quartet_DNA_ILM_Nova_ARD_LCL5_6_20190111, \ | |||
| row.Quartet_DNA_ILM_Nova_BRG_LCL5_1_20180930,row.Quartet_DNA_ILM_Nova_BRG_LCL5_2_20180930,row.Quartet_DNA_ILM_Nova_BRG_LCL5_3_20180930, \ | |||
| row.Quartet_DNA_ILM_Nova_WUX_LCL5_1_20190917,row.Quartet_DNA_ILM_Nova_WUX_LCL5_2_20190917,row.Quartet_DNA_ILM_Nova_WUX_LCL5_3_20190917, \ | |||
| row.Quartet_DNA_ILM_XTen_ARD_LCL5_1_20170403,row.Quartet_DNA_ILM_XTen_ARD_LCL5_2_20170403,row.Quartet_DNA_ILM_XTen_ARD_LCL5_3_20170403, \ | |||
| row.Quartet_DNA_ILM_XTen_NVG_LCL5_1_20170329,row.Quartet_DNA_ILM_XTen_NVG_LCL5_2_20170329,row.Quartet_DNA_ILM_XTen_NVG_LCL5_3_20170329, \ | |||
| row.Quartet_DNA_ILM_XTen_WUX_LCL5_1_20170216,row.Quartet_DNA_ILM_XTen_WUX_LCL5_2_20170216,row.Quartet_DNA_ILM_XTen_WUX_LCL5_3_20170216] | |||
| lcl6_list = [row.Quartet_DNA_BGI_SEQ2000_BGI_LCL6_1_20180518,row.Quartet_DNA_BGI_SEQ2000_BGI_LCL6_2_20180530,row.Quartet_DNA_BGI_SEQ2000_BGI_LCL6_3_20180530, \ | |||
| row.Quartet_DNA_BGI_T7_WGE_LCL6_1_20191105,row.Quartet_DNA_BGI_T7_WGE_LCL6_2_20191105,row.Quartet_DNA_BGI_T7_WGE_LCL6_3_20191105, \ | |||
| row.Quartet_DNA_ILM_Nova_ARD_LCL6_1_20181108,row.Quartet_DNA_ILM_Nova_ARD_LCL6_2_20181108,row.Quartet_DNA_ILM_Nova_ARD_LCL6_3_20181108, \ | |||
| row.Quartet_DNA_ILM_Nova_ARD_LCL6_4_20190111,row.Quartet_DNA_ILM_Nova_ARD_LCL6_5_20190111,row.Quartet_DNA_ILM_Nova_ARD_LCL6_6_20190111, \ | |||
| row.Quartet_DNA_ILM_Nova_BRG_LCL6_1_20180930,row.Quartet_DNA_ILM_Nova_BRG_LCL6_2_20180930,row.Quartet_DNA_ILM_Nova_BRG_LCL6_3_20180930, \ | |||
| row.Quartet_DNA_ILM_Nova_WUX_LCL6_1_20190917,row.Quartet_DNA_ILM_Nova_WUX_LCL6_2_20190917,row.Quartet_DNA_ILM_Nova_WUX_LCL6_3_20190917, \ | |||
| row.Quartet_DNA_ILM_XTen_ARD_LCL6_1_20170403,row.Quartet_DNA_ILM_XTen_ARD_LCL6_2_20170403,row.Quartet_DNA_ILM_XTen_ARD_LCL6_3_20170403, \ | |||
| row.Quartet_DNA_ILM_XTen_NVG_LCL6_1_20170329,row.Quartet_DNA_ILM_XTen_NVG_LCL6_2_20170329,row.Quartet_DNA_ILM_XTen_NVG_LCL6_3_20170329, \ | |||
| row.Quartet_DNA_ILM_XTen_WUX_LCL6_1_20170216,row.Quartet_DNA_ILM_XTen_WUX_LCL6_2_20170216,row.Quartet_DNA_ILM_XTen_WUX_LCL6_3_20170216] | |||
| lcl7_list = [row.Quartet_DNA_BGI_SEQ2000_BGI_LCL7_1_20180518,row.Quartet_DNA_BGI_SEQ2000_BGI_LCL7_2_20180530,row.Quartet_DNA_BGI_SEQ2000_BGI_LCL7_3_20180530, \ | |||
| row.Quartet_DNA_BGI_T7_WGE_LCL7_1_20191105,row.Quartet_DNA_BGI_T7_WGE_LCL7_2_20191105,row.Quartet_DNA_BGI_T7_WGE_LCL7_3_20191105, \ | |||
| row.Quartet_DNA_ILM_Nova_ARD_LCL7_1_20181108,row.Quartet_DNA_ILM_Nova_ARD_LCL7_2_20181108,row.Quartet_DNA_ILM_Nova_ARD_LCL7_3_20181108, \ | |||
| row.Quartet_DNA_ILM_Nova_ARD_LCL7_4_20190111,row.Quartet_DNA_ILM_Nova_ARD_LCL7_5_20190111,row.Quartet_DNA_ILM_Nova_ARD_LCL7_6_20190111, \ | |||
| row.Quartet_DNA_ILM_Nova_BRG_LCL7_1_20180930,row.Quartet_DNA_ILM_Nova_BRG_LCL7_2_20180930,row.Quartet_DNA_ILM_Nova_BRG_LCL7_3_20180930, \ | |||
| row.Quartet_DNA_ILM_Nova_WUX_LCL7_1_20190917,row.Quartet_DNA_ILM_Nova_WUX_LCL7_2_20190917,row.Quartet_DNA_ILM_Nova_WUX_LCL7_3_20190917, \ | |||
| row.Quartet_DNA_ILM_XTen_ARD_LCL7_1_20170403,row.Quartet_DNA_ILM_XTen_ARD_LCL7_2_20170403,row.Quartet_DNA_ILM_XTen_ARD_LCL7_3_20170403, \ | |||
| row.Quartet_DNA_ILM_XTen_NVG_LCL7_1_20170329,row.Quartet_DNA_ILM_XTen_NVG_LCL7_2_20170329,row.Quartet_DNA_ILM_XTen_NVG_LCL7_3_20170329, \ | |||
| row.Quartet_DNA_ILM_XTen_WUX_LCL7_1_20170216,row.Quartet_DNA_ILM_XTen_WUX_LCL7_2_20170216,row.Quartet_DNA_ILM_XTen_WUX_LCL7_3_20170216] | |||
| lcl8_list = [row.Quartet_DNA_BGI_SEQ2000_BGI_LCL8_1_20180518,row.Quartet_DNA_BGI_SEQ2000_BGI_LCL8_2_20180530,row.Quartet_DNA_BGI_SEQ2000_BGI_LCL8_3_20180530, \ | |||
| row.Quartet_DNA_BGI_T7_WGE_LCL8_1_20191105,row.Quartet_DNA_BGI_T7_WGE_LCL8_2_20191105,row.Quartet_DNA_BGI_T7_WGE_LCL8_3_20191105, \ | |||
| row.Quartet_DNA_ILM_Nova_ARD_LCL8_1_20181108,row.Quartet_DNA_ILM_Nova_ARD_LCL8_2_20181108,row.Quartet_DNA_ILM_Nova_ARD_LCL8_3_20181108, \ | |||
| row.Quartet_DNA_ILM_Nova_ARD_LCL8_4_20190111,row.Quartet_DNA_ILM_Nova_ARD_LCL8_5_20190111,row.Quartet_DNA_ILM_Nova_ARD_LCL8_6_20190111, \ | |||
| row.Quartet_DNA_ILM_Nova_BRG_LCL8_1_20180930,row.Quartet_DNA_ILM_Nova_BRG_LCL8_2_20180930,row.Quartet_DNA_ILM_Nova_BRG_LCL8_3_20180930, \ | |||
| row.Quartet_DNA_ILM_Nova_WUX_LCL8_1_20190917,row.Quartet_DNA_ILM_Nova_WUX_LCL8_2_20190917,row.Quartet_DNA_ILM_Nova_WUX_LCL8_3_20190917, \ | |||
| row.Quartet_DNA_ILM_XTen_ARD_LCL8_1_20170403,row.Quartet_DNA_ILM_XTen_ARD_LCL8_2_20170403,row.Quartet_DNA_ILM_XTen_ARD_LCL8_3_20170403, \ | |||
| row.Quartet_DNA_ILM_XTen_NVG_LCL8_1_20170329,row.Quartet_DNA_ILM_XTen_NVG_LCL8_2_20170329,row.Quartet_DNA_ILM_XTen_NVG_LCL8_3_20170329, \ | |||
| row.Quartet_DNA_ILM_XTen_WUX_LCL8_1_20170216,row.Quartet_DNA_ILM_XTen_WUX_LCL8_2_20170216,row.Quartet_DNA_ILM_XTen_WUX_LCL8_3_20170216] | |||
| # LCL5 | |||
| LCL5_pcr_consensus, LCL5_pcr_free_consensus, LCL5_mendelian_num, LCL5_consensus_call, LCL5_consensus_alt_seq, LCL5_alt, LCL5_dp, LCL5_detected_num = consensus_call(lcl5_list,mendelian_list,row.ALT) | |||
| if LCL5_mendelian_num != '.': | |||
| LCL5_output = row.CHROM + '\t' + str(row.POS) + '\t' + '.' + '\t' + row.REF + '\t' + LCL5_consensus_alt_seq + '\t' + '.' + '\t' + '.' + '\t' +'VOTED=' + str(LCL5_mendelian_num) + '\t' + 'GT:ALT:DP' + '\t' + LCL5_consensus_call + ':' + str(LCL5_alt) + ':' + str(LCL5_dp) + '\n' | |||
| benchmark_LCL5.write(LCL5_output) | |||
| # LCL6 | |||
| LCL6_pcr_consensus, LCL6_pcr_free_consensus, LCL6_mendelian_num, LCL6_consensus_call, LCL6_consensus_alt_seq, LCL6_alt, LCL6_dp, LCL6_detected_num = consensus_call(lcl6_list,mendelian_list,row.ALT) | |||
| if LCL6_mendelian_num != '.': | |||
| LCL6_output = row.CHROM + '\t' + str(row.POS) + '\t' + '.' + '\t' + row.REF + '\t' + LCL6_consensus_alt_seq + '\t' + '.' + '\t' + '.' + '\t' +'VOTED=' + str(LCL6_mendelian_num) + '\t' + 'GT:ALT:DP' + '\t' + LCL6_consensus_call + ':' + str(LCL6_alt) + ':' + str(LCL6_dp) + '\n' | |||
| benchmark_LCL6.write(LCL6_output) | |||
| # LCL7 | |||
| LCL7_pcr_consensus, LCL7_pcr_free_consensus, LCL7_mendelian_num, LCL7_consensus_call, LCL7_consensus_alt_seq, LCL7_alt, LCL7_dp, LCL7_detected_num = consensus_call(lcl7_list,mendelian_list,row.ALT) | |||
| if LCL7_mendelian_num != '.': | |||
| LCL7_output = row.CHROM + '\t' + str(row.POS) + '\t' + '.' + '\t' + row.REF + '\t' + LCL7_consensus_alt_seq + '\t' + '.' + '\t' + '.' + '\t' +'VOTED=' + str(LCL7_mendelian_num) + '\t' + 'GT:ALT:DP' + '\t' + LCL7_consensus_call + ':' + str(LCL7_alt) + ':' + str(LCL7_dp) + '\n' | |||
| benchmark_LCL7.write(LCL7_output) | |||
| # LCL8 | |||
| LCL8_pcr_consensus, LCL8_pcr_free_consensus, LCL8_mendelian_num, LCL8_consensus_call, LCL8_consensus_alt_seq, LCL8_alt, LCL8_dp, LCL8_detected_num = consensus_call(lcl8_list,mendelian_list,row.ALT) | |||
| if LCL8_mendelian_num != '.': | |||
| LCL8_output = row.CHROM + '\t' + str(row.POS) + '\t' + '.' + '\t' + row.REF + '\t' + LCL8_consensus_alt_seq + '\t' + '.' + '\t' + '.' + '\t' +'VOTED=' + str(LCL8_mendelian_num) + '\t' + 'GT:ALT:DP' + '\t' + LCL8_consensus_call + ':' + str(LCL8_alt) + ':' + str(LCL8_dp) + '\n' | |||
| benchmark_LCL8.write(LCL8_output) | |||
| # all data | |||
| all_output = row.CHROM + '\t' + str(row.POS) + '\t' + LCL5_pcr_consensus + '\t' + LCL5_pcr_free_consensus + '\t' + str(LCL5_mendelian_num) + '\t' + LCL5_consensus_call + '\t' + LCL5_consensus_alt_seq + '\t' + str(LCL5_alt) + '\t' + str(LCL5_dp) + '\t' + str(LCL5_detected_num) + '\t' +\ | |||
| LCL6_pcr_consensus + '\t' + LCL6_pcr_free_consensus + '\t' + str(LCL6_mendelian_num) + '\t' + LCL6_consensus_call + '\t' + LCL6_consensus_alt_seq + '\t' + str(LCL6_alt) + '\t' + str(LCL6_dp) + '\t' + str(LCL6_detected_num) + '\t' +\ | |||
| LCL7_pcr_consensus + '\t' + LCL7_pcr_free_consensus + '\t' + str(LCL7_mendelian_num) + '\t' + LCL7_consensus_call + '\t' + LCL7_consensus_alt_seq + '\t' + str(LCL7_alt) + '\t' + str(LCL7_dp) + '\t' + str(LCL7_detected_num) + '\t' +\ | |||
| LCL8_pcr_consensus + '\t' + LCL8_pcr_free_consensus + '\t' + str(LCL8_mendelian_num) + '\t' + LCL8_consensus_call + '\t' + LCL8_consensus_alt_seq + '\t' + str(LCL8_alt) + '\t' + str(LCL8_dp) + '\t' + str(LCL8_detected_num) + '\n' | |||
| all_sample_outfile.write(all_output) | |||
+ 1
- 0
family.tsv
View File
| @@ -0,0 +1 @@ | |||
| #LCL5vcf LCL6vcf LCL7vcf LCL8vcf LCL5name LCL6name LCL7name LCL8name familyname | |||
+ 10
- 0
inputs
View File
| @@ -0,0 +1,10 @@ | |||
| { | |||
| "{{ project_name }}.fasta": "GRCh38.d1.vd1.fa", | |||
| "{{ project_name }}.replicate_consensus.docker": "registry-vpc.cn-shanghai.aliyuncs.com/pgx-docker-registry/high_confidence_call_manuscript:v1.4", | |||
| "{{ project_name }}.chromo_file": "{{ chromo_file }}", | |||
| "{{ project_name }}.mendelian.docker": "registry-vpc.cn-shanghai.aliyuncs.com/pgx-docker-registry/vbt:v1.1", | |||
| "{{ project_name }}.disk_size": "150", | |||
| "{{ project_name }}.chromo": "{{ chromo }}", | |||
| "{{ project_name }}.cluster_config": "OnDemand bcs.b4.xlarge img-ubuntu-vpc", | |||
| "{{ project_name }}.ref_dir": "oss://chinese-quartet/quartet-storage-data/reference_data/" | |||
| } | |||
BIN
pictures/.DS_Store
View File
BIN
pictures/workflow.png
View File
{kind=link}
| Before | After |
|---|---|
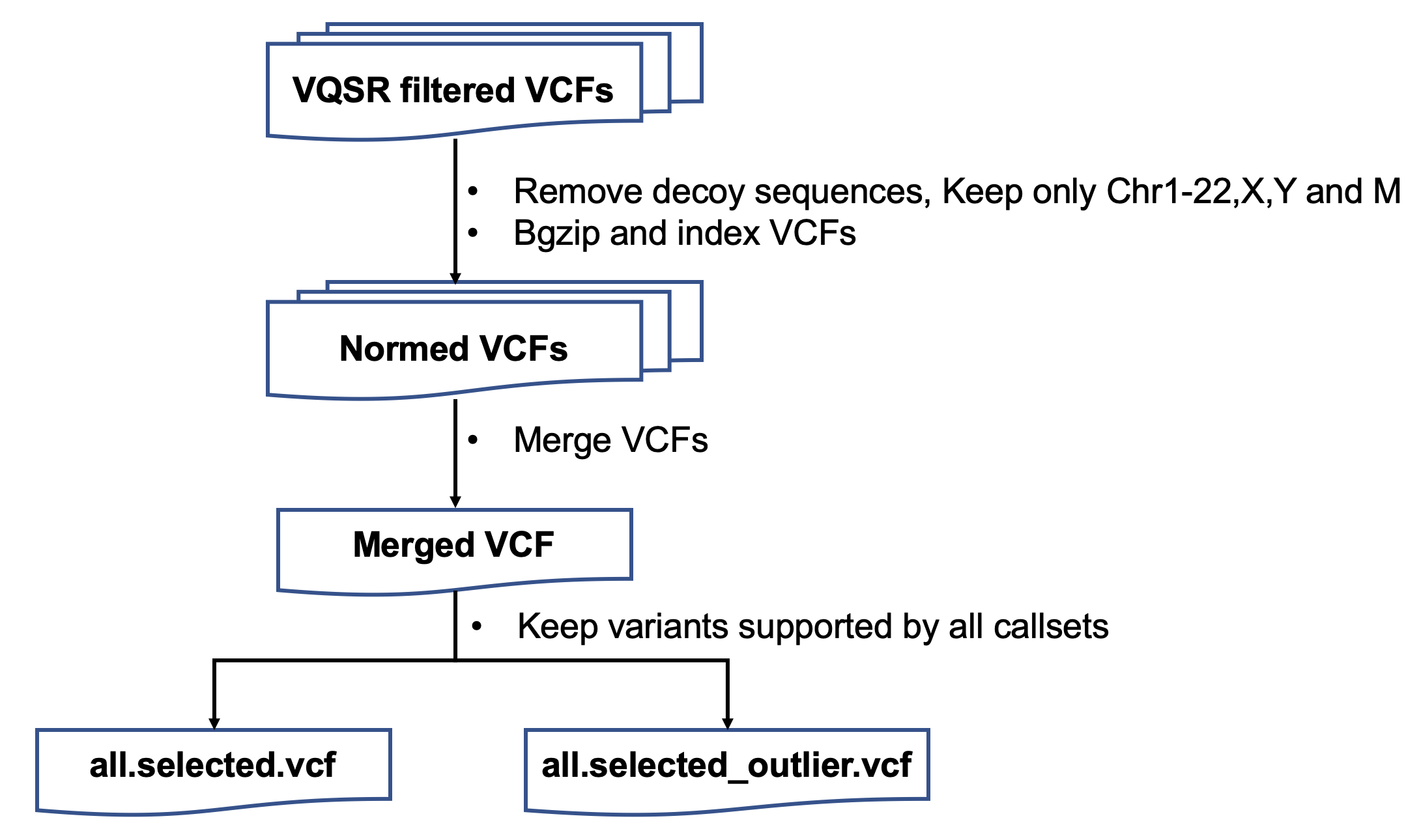
|
|
| Width: 2178 | Height: 1290 | Size: 180KB |
BIN
tasks/.DS_Store
View File
+ 46
- 0
tasks/mendelian.wdl
View File
| @@ -0,0 +1,46 @@ | |||
| task mendelian { | |||
| File consensus_vcf | |||
| File ref_dir | |||
| String fasta | |||
| String chromo | |||
| String docker | |||
| String cluster_config | |||
| String disk_size | |||
| command <<< | |||
| export LD_LIBRARY_PATH=/opt/htslib-1.9 | |||
| nt=$(nproc) | |||
| # prepare ped file, D5 | |||
| echo "${chromo} LCL8_consensus_calls 0 0 2 -9 | |||
| ${chromo} LCL7_consensus_calls 0 0 1 -9 | |||
| ${chromo} LCL5_consensus_calls LCL7_consensus_calls LCL8_consensus_calls 2 -9" > ${chromo}.D5.ped | |||
| mkdir VBT_D5 | |||
| /opt/VBT-TrioAnalysis/vbt mendelian -ref ${ref_dir}/${fasta} -mother ${consensus_vcf} -father ${consensus_vcf} -child ${consensus_vcf} -pedigree ${chromo}.D5.ped -outDir VBT_D5 -out-prefix ${chromo}.D5 --output-violation-regions -thread-count $nt | |||
| cat VBT_D5/${chromo}.D5_trio.vcf > ${chromo}.D5.vcf | |||
| # prepare ped file, D6 | |||
| echo "${chromo} LCL8_consensus_calls 0 0 2 -9 | |||
| ${chromo} LCL7_consensus_calls 0 0 1 -9 | |||
| ${chromo} LCL6_consensus_calls LCL7_consensus_calls LCL8_consensus_calls 2 -9" > ${chromo}.D6.ped | |||
| mkdir VBT_D6 | |||
| /opt/VBT-TrioAnalysis/vbt mendelian -ref ${ref_dir}/${fasta} -mother ${consensus_vcf} -father ${consensus_vcf} -child ${consensus_vcf} -pedigree ${chromo}.D5.ped -outDir VBT_D6 -out-prefix ${chromo}.D6 --output-violation-regions -thread-count $nt | |||
| cat VBT_D6/${chromo}.D6_trio.vcf > ${chromo}.D6.vcf | |||
| >>> | |||
| runtime { | |||
| docker:docker | |||
| cluster: cluster_config | |||
| systemDisk: "cloud_ssd 40" | |||
| dataDisk: "cloud_ssd " + disk_size + " /cromwell_root/" | |||
| } | |||
| output { | |||
| Array[File] D5_mendelian = glob("VBT_D5/*") | |||
| Array[File] D6_mendelian = glob("VBT_D6/*") | |||
| File D5_trio_vcf = "${chromo}.D5.vcf" | |||
| File D6_trio_vcf = "${chromo}.D6.vcf" | |||
| File family_vcf = "${chromo}.vcf" | |||
| } | |||
| } | |||
+ 25
- 0
tasks/replicate_consensus.wdl
View File
| @@ -0,0 +1,25 @@ | |||
| task replicate_consensus { | |||
| File chromo_file | |||
| String chromo | |||
| String docker | |||
| String cluster_config | |||
| String disk_size | |||
| command <<< | |||
| python /opt/replicates_consensus.py -vcf ${chromo_file} -prefix ${chromo} | |||
| >>> | |||
| runtime { | |||
| docker:docker | |||
| cluster: cluster_config | |||
| systemDisk: "cloud_ssd 40" | |||
| dataDisk: "cloud_ssd " + disk_size + " /cromwell_root/" | |||
| } | |||
| output { | |||
| File chromo_consensus = "${chromo}_all_summary.txt" | |||
| File consensus_vcf = "${chromo}_consensus.vcf" | |||
| } | |||
| } | |||
+ 36
- 0
tasks/two_family_merge.wdl
View File
| @@ -0,0 +1,36 @@ | |||
| task two_family_merge { | |||
| File LCL5_trio_vcf | |||
| File LCL6_trio_vcf | |||
| File genotype_file | |||
| String family_chromo_name | |||
| String docker | |||
| String cluster_config | |||
| String disk_size | |||
| command <<< | |||
| cat ${LCL5_trio_vcf} | grep -v '##' > ${family_chromo_name}.LCL5.txt | |||
| cat ${LCL6_trio_vcf} | grep -v '##' > ${family_chromo_name}.LCL6.txt | |||
| cat ${genotype_file} | grep -v '##' | awk ' | |||
| BEGIN { OFS = "\t" } | |||
| NF > 2 && FNR > 1 { | |||
| for ( i=9; i<=NF; i++ ) { | |||
| split($i,a,":") ;$i = a[1]; | |||
| } | |||
| } | |||
| { print } | |||
| ' | cut -f1,2,4,5,10- > ${family_chromo_name}.genotype.txt | |||
| python /opt/merge_two_family_with_genotype.py -LCL5 ${family_chromo_name}.LCL5.txt -LCL6 ${family_chromo_name}.LCL6.txt -genotype ${family_chromo_name}.genotype.txt -family ${family_chromo_name} | |||
| >>> | |||
| runtime { | |||
| docker:docker | |||
| cluster: cluster_config | |||
| systemDisk: "cloud_ssd 40" | |||
| dataDisk: "cloud_ssd " + disk_size + " /cromwell_root/" | |||
| } | |||
| output { | |||
| File family_mendelian_info = "${family_chromo_name}.txt" | |||
| } | |||
| } | |||
+ 29
- 0
workflow.wdl
View File
| @@ -0,0 +1,29 @@ | |||
| import "./tasks/replicate_consensus.wdl" as replicate_consensus | |||
| import "./tasks/mendelian.wdl" as mendelian | |||
| workflow {{ project_name }} { | |||
| File ref_dir | |||
| String fasta | |||
| File chromo_file | |||
| String chromo | |||
| String cluster_config | |||
| String disk_size | |||
| call replicate_consensus.replicate_consensus as replicate_consensus { | |||
| input: | |||
| chromo_file=chromo_file, | |||
| chromo=chromo, | |||
| cluster_config=cluster_config, | |||
| disk_size=disk_size | |||
| } | |||
| call mendelian.mendelian as mendelian { | |||
| input: | |||
| consensus_vcf=replicate_consensus.consensus_vcf, | |||
| ref_dir=ref_dir, | |||
| fasta=fasta, | |||
| chromo=chromo, | |||
| cluster_config=cluster_config, | |||
| disk_size=disk_size | |||
| } | |||
| } | |||
Loading…