
 LUYAO REN
6 年前
LUYAO REN
6 年前
当前提交
126c76a7bb
共有 14 个文件被更改,包括 678 次插入 和 0 次删除
+ 103
- 0
README.md
查看文件
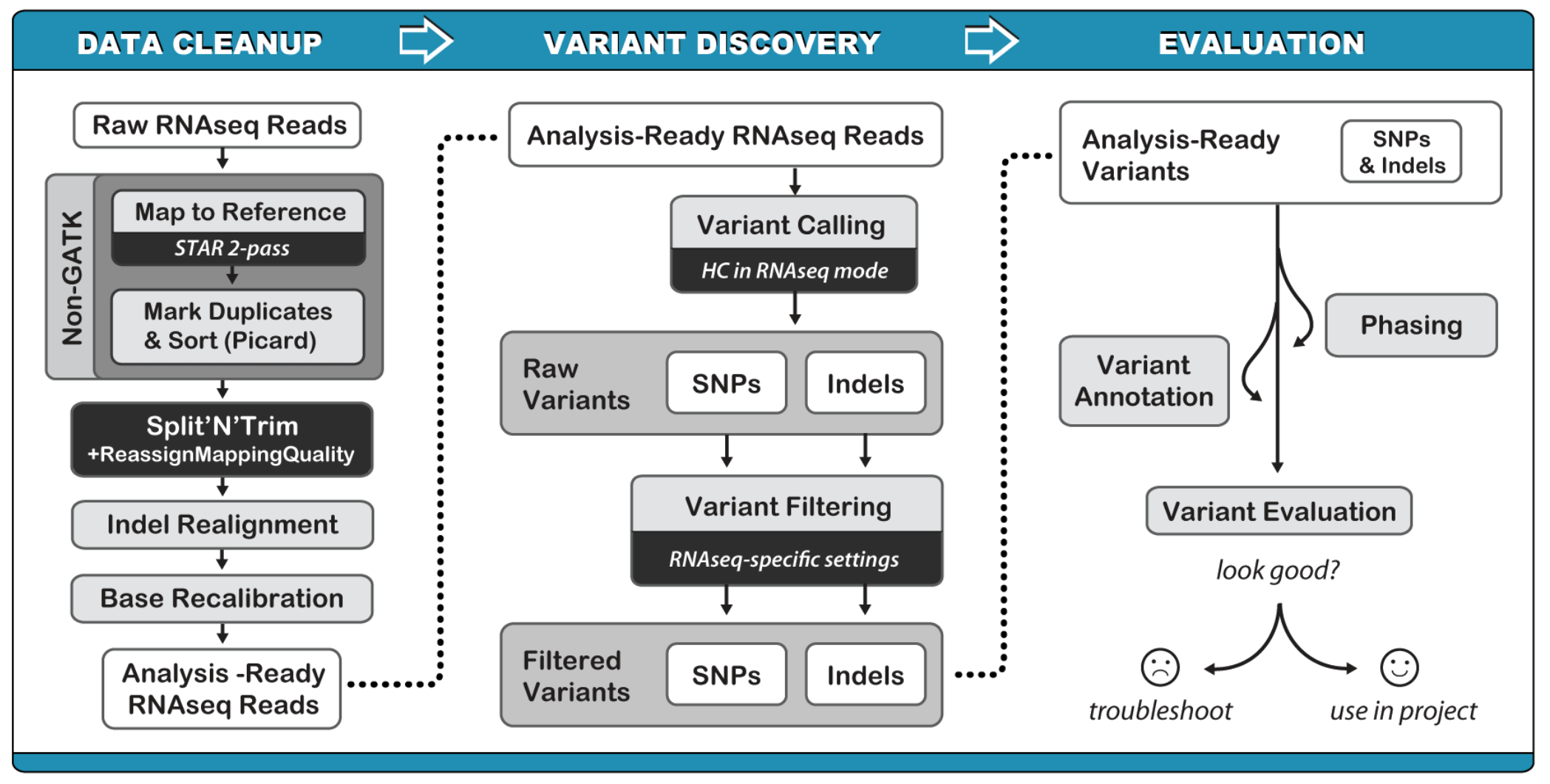
| # RNAseq variant calling | |||||
| ####RNAseq variant calling pipeline: | |||||
|  | |||||
| **(1) Mapping to the reference genome (STAR)** | |||||
| Aligning RNAseq data to a reference genome is complicates by RNA splicing, [GATK RNAseq variant calling best practice](<https://software.broadinstitute.org/gatk/documentation/article.php?id=3891>) recommend [STAR](<https://github.com/alexdobin/STAR>). | |||||
| Generate genome index files: | |||||
| ```bash | |||||
| genomeDir=/path/to/GRCh38 | |||||
| mkdir $genomeDir | |||||
| STAR --runMode genomeGenerate\ | |||||
| --genomeDir $genomeDir\ | |||||
| --genomeFastaFiles hg19.fa\ | |||||
| --runThreadN <n> | |||||
| ``` | |||||
| Mapping reads to the genome: | |||||
| The author recommend running STAR in the 2-pass mode for the most sensitive novel junction discovery. It does not increase the number of detected novel junctions, but allows to detect more splices reads mapping to novel junctions. The basic idea is to run 1st pass of STAR mapping with the usual paraments, then collect the junctions detected inthe first pass, and use them as "annotated" junctions for the 2nd pass mapping | |||||
| ```bash | |||||
| # 1. 1st pass | |||||
| runDir=/path/to/1pass | |||||
| mkdir $runDir | |||||
| cd $runDir | |||||
| STAR --genomeDir $genomeDir --readFilesIn mate1.fq mate2.fq --runThreadN <n> | |||||
| # For the 2-pass STAR, a new index is then created using splice junstion information contained inthe file SJ.out.tab from the first pass | |||||
| genomeDir=/path/to/hg19_2pass | |||||
| mkdir $genomeDir | |||||
| STAR --runMode genomeGenerate --genomeDir $genomeDir --genomeFastaFiles hg19.fa \ | |||||
| --sjdbFileChrStartEnd /path/to/1pass/SJ.out.tab --sjdbOverhang 75 --runThreadN <n> | |||||
| # 3. 2nd pass | |||||
| runDir=/path/to/2pass | |||||
| mkdir $runDir | |||||
| cd $runDir | |||||
| STAR --genomeDir $genomeDir --readFilesIn mate1.fq mate2.fq --runThreadN <n> | |||||
| ``` | |||||
| **(2) Convert alignment output SAM to BAM, and add read groups ([picard](<https://software.broadinstitute.org/gatk/documentation/tooldocs/current/picard_sam_AddOrReplaceReadGroups.php>)) and index bam ([samtools](<http://www.htslib.org/doc/samtools.html>))** | |||||
| ```bash | |||||
| java -jar picard.jar AddOrReplaceReadGroups I=star_output.sam O=rg_added_sorted.bam SO=coordinate RGID=id RGLB=library RGPL=platform RGPU=machine RGSM=sample | |||||
| # index bam and get .bai | |||||
| samtools index rg_added_sorted.bam | |||||
| ``` | |||||
| **(3) Remove deplicates** | |||||
| ```bash | |||||
| sentieon driver -t NUMBER_THREADS -i SORTED_BAM \ | |||||
| --algo LocusCollector --fun score_info SCORE.gz | |||||
| sentieon driver -t NUMBER_THREADS -i SORTED_BAM \ | |||||
| --algo Dedup --rmdup --score_info SCORE.gz \ | |||||
| --metrics DEDUP_METRIC_TXT DEDUPED_BAM | |||||
| ``` | |||||
| **(4) Split reads at junction** | |||||
| This step slits the RNA reads into exon segments by getting rid of Ns while maintaining grouping information, and hard-clips any sequences overhanging into the intron regions. Additionally, the step will reassign the mapping qualities from STAR to be consistent with what is expected in subsequent steps by converting from quality 255 to 60. | |||||
| ```bash | |||||
| sentieon driver -t NUMBER_THREADS -r REFERENCE -i DEDUPED_BAM \ | |||||
| --algo RNASplitReadsAtJunction --reassign_mapq 255:60 SPLIT_BAM | |||||
| ``` | |||||
| **(5) Base quality score recalibration ** | |||||
| ```bash | |||||
| sentieon driver -r $fasta -t $nt -i SPLIT_BAM --algo QualCal -k $dbsnp -k $known_Mills_indels -k $known_1000G_indels recal_data.table | |||||
| sentieon driver -r $fasta -t $nt -i SPLIT_BAM -q recal_data.table --algo QualCal -k $dbsnp -k $known_Mills_indels -k $known_1000G_indels recal_data.table.post | |||||
| sentieon driver -t $nt --algo QualCal --plot --before recal_data.table --after recal_data.table.post recal.csv | |||||
| sentieon plot QualCal -o recal_plots.pdf recal.csv | |||||
| ``` | |||||
| **(6) Variant calling** | |||||
| ```bash | |||||
| sentieon driver -t NUMBER_THREADS -r REFERENCE -i SPLIT_BAM \ | |||||
| -q RECAL_DATA.TABLE --algo Haplotyper --trim_soft_clip \ | |||||
| --call_conf 20 --emit_conf 20 [-d dbSNP] VARIANT_VCF | |||||
| ``` | |||||
| **(7) Variant Filtering** | |||||
| Hard filtration is applied, for GATK do not yet have the RNAseq training/truth resources that would be needed to run VQSR. | |||||
| - `-window 35 -cluster 2` Remove clusters of at least 3 SNPs that are within a window of 35 bases between them | |||||
| - `FS > 30.0` Fisher Strand values | |||||
| - `QD < 2.0`Qual By Depth values | |||||
| ```bash | |||||
| java -jar GenomeAnalysisTK.jar -T VariantFiltration -R hg_19.fasta -V input.vcf -window 35 -cluster 3 -filterName FS -filter "FS > 30.0" -filterName QD -filter "QD < 2.0" -o output.vcf | |||||
| ``` | |||||
+ 24
- 0
inputs
查看文件
| { | |||||
| "{{ project_name }}.SENTIEON_INSTALL_DIR": "/opt/sentieon-genomics", | |||||
| "{{ project_name }}.fasta": "GRCh38.d1.vd1.fa", | |||||
| "{{ project_name }}.PIdocker": "registry-vpc.cn-shanghai.aliyuncs.com/pgx-docker-registry/picard", | |||||
| "{{ project_name }}.platform": "ILLUMINA", | |||||
| "{{ project_name }}.dbsnp_dir": "oss://pgx-reference-data/GRCh38.d1.vd1/", | |||||
| "{{ project_name }}.disk_size": "{{ disk_size }}", | |||||
| "{{ project_name }}.SAdocker": "registry-vpc.cn-shanghai.aliyuncs.com/pgx-docker-registry/star", | |||||
| "{{ project_name }}.fastq_1": "{{ read1 }}", | |||||
| "{{ project_name }}.machine": "{{ machine }}", | |||||
| "{{ project_name }}.STdocker": "registry.cn-shanghai.aliyuncs.com/pgx-docker-registry/sentieon-genomics:v2018.08.01", | |||||
| "{{ project_name }}.library": "{{ library }}", | |||||
| "{{ project_name }}.fastq_2": "{{ read1 }}", | |||||
| "{{ project_name }}.dbmills_dir": "oss://pgx-reference-data/GRCh38.d1.vd1/", | |||||
| "{{ project_name }}.cluster_config": "{{ cluster if cluster != '' else 'OnDemand ecs.sn1ne.8xlarge img-ubuntu-vpc' }}", | |||||
| "{{ project_name }}.SAref_dir": "File", | |||||
| "{{ project_name }}.SAMdocker": "registry-vpc.cn-shanghai.aliyuncs.com/pgx-docker-registry/samtools", | |||||
| "{{ project_name }}.STref_dir": "oss://chinese-quartet/quartet-storage-data/reference_data/STAR_GRCh38/", | |||||
| "{{ project_name }}.db_mills": "Mills_and_1000G_gold_standard.indels.hg38.vcf", | |||||
| "{{ project_name }}.sample": "{{ sample }}", | |||||
| "{{ project_name }}.dbsnp": "dbsnp_146.hg38.vcf", | |||||
| "{{ project_name }}.id": "{{ id }}", | |||||
| "{{ project_name }}.GATKdocker": "registry.cn-shanghai.aliyuncs.com/pgx-docker-registry/gatk:v2019.01", | |||||
| } |
二进制
pictures/Screen Shot 2019-06-14 at 9.56.40 AM.png
查看文件
{kind=link}
| 之前 | 之后 |
|---|---|
|
|
| 宽度: 2097 | 高度: 1061 | 大小: 470KB |
+ 48
- 0
tasks/BQSR.wdl
查看文件
| task BQSR { | |||||
| String sample | |||||
| String SENTIEON_INSTALL_DIR | |||||
| String fasta | |||||
| File dbsnp_dir | |||||
| String dbsnp | |||||
| File dbmills_dir | |||||
| String db_mills | |||||
| File Split_bam | |||||
| File Split_bam_index | |||||
| File STref_dir | |||||
| String STdocker | |||||
| String cluster_config | |||||
| String disk_size | |||||
| command <<< | |||||
| set -o pipefail | |||||
| set -e | |||||
| export SENTIEON_LICENSE=192.168.0.55:8990 | |||||
| nt=$(nproc) | |||||
| ${SENTIEON_INSTALL_DIR}/bin/sentieon driver -r ${STref_dir}/${fasta} -t $nt -i ${Split_bam} --algo QualCal -k ${dbsnp_dir}/${dbsnp} -k ${dbmills_dir}/${db_mills} ${sample}_recal_data.table | |||||
| ${SENTIEON_INSTALL_DIR}/bin/sentieon driver -r ${STref_dir}/${fasta} -t $nt -i ${Split_bam} -q ${sample}_recal_data.table --algo QualCal -k ${dbsnp_dir}/${dbsnp} -k ${dbmills_dir}/${db_mills} ${sample}_recal_data.table.post --algo ReadWriter ${sample}.sorted.deduped.recaled.bam | |||||
| ${SENTIEON_INSTALL_DIR}/bin/sentieon driver -t $nt --algo QualCal --plot --before ${sample}_recal_data.table --after ${sample}_recal_data.table.post ${sample}_recal_data.csv | |||||
| ${SENTIEON_INSTALL_DIR}/bin/sentieon plot QualCal -o ${sample}_bqsrreport.pdf ${sample}_recal_data.csv | |||||
| >>> | |||||
| runtime { | |||||
| dockerTag:STdocker | |||||
| cluster: cluster_config | |||||
| systemDisk: "cloud_ssd 40" | |||||
| dataDisk: "cloud_ssd " + disk_size + " /cromwell_root/" | |||||
| } | |||||
| output { | |||||
| File recal_table = "${sample}_recal_data.table" | |||||
| File recal_post = "${sample}_recal_data.table.post" | |||||
| File recaled_bam = "${sample}.sorted.deduped.recaled.bam" | |||||
| File recaled_bam_index = "${sample}.sorted.deduped.recaled.bam.bai" | |||||
| File recal_csv = "${sample}_recal_data.csv" | |||||
| File bqsrreport_pdf = "${sample}_bqsrreport.pdf" | |||||
| } | |||||
| } |
+ 40
- 0
tasks/Dedup.wdl
查看文件
| task Dedup { | |||||
| String SENTIEON_INSTALL_DIR | |||||
| String sample | |||||
| File sorted_bam | |||||
| File sorted_bam_index | |||||
| String STdocker | |||||
| String cluster_config | |||||
| String disk_size | |||||
| command <<< | |||||
| set -o pipefail | |||||
| set -e | |||||
| export SENTIEON_LICENSE=192.168.0.55:8990 | |||||
| nt=$(nproc) | |||||
| ${SENTIEON_INSTALL_DIR}/bin/sentieon driver -t $nt -i ${sorted_bam} --algo LocusCollector --fun score_info ${sample}_score.txt | |||||
| ${SENTIEON_INSTALL_DIR}/bin/sentieon driver -t $nt -i ${sorted_bam} --algo Dedup --rmdup --score_info ${sample}_score.txt --metrics ${sample}_dedup_metrics.txt ${sample}.sorted.deduped.bam | |||||
| >>> | |||||
| runtime { | |||||
| docker:STdocker | |||||
| cluster: cluster_config | |||||
| systemDisk: "cloud_ssd 40" | |||||
| dataDisk: "cloud_ssd " + disk_size + " /cromwell_root/" | |||||
| } | |||||
| output { | |||||
| File score = "${sample}_score.txt" | |||||
| File dedup_metrics = "${sample}_dedup_metrics.txt" | |||||
| File Dedup_bam = "${sample}.sorted.deduped.bam" | |||||
| File Dedup_bam_index = "${sample}.sorted.deduped.bam.bai" | |||||
| } | |||||
| } | |||||
+ 35
- 0
tasks/Haplotyper.wdl
查看文件
| task Haplotyper { | |||||
| String SENTIEON_INSTALL_DIR | |||||
| String fasta | |||||
| File recaled_bam | |||||
| File recaled_bam_index | |||||
| File dbsnp_dir | |||||
| String dbsnp | |||||
| File STref_dir | |||||
| String sample | |||||
| String STdocker | |||||
| String cluster_config | |||||
| String disk_size | |||||
| command <<< | |||||
| set -o pipefail | |||||
| set -e | |||||
| export SENTIEON_LICENSE=192.168.0.55:8990 | |||||
| nt=$(nproc) | |||||
| ${SENTIEON_INSTALL_DIR}/bin/sentieon driver -r ${STref_dir}/${fasta} -t $nt -i ${recaled_bam} --algo Haplotyper -d ${dbsnp_dir}/${dbsnp} --trim_soft_clip --call_conf 20 --emit_conf 20 ${sample}_hc.vcf | |||||
| >>> | |||||
| runtime { | |||||
| dockerTag:STdocker | |||||
| cluster: cluster_config | |||||
| systemDisk: "cloud_ssd 40" | |||||
| dataDisk: "cloud_ssd " + disk_size + " /cromwell_root/" | |||||
| } | |||||
| output { | |||||
| File vcf = "${sample}_hc.vcf" | |||||
| File vcf_idx = "${sample}_hc.vcf.idx" | |||||
| } | |||||
| } | |||||
+ 37
- 0
tasks/Hardfiltration.wdl
查看文件
| task Hardfiltration { | |||||
| File vcf_file | |||||
| File vcf_index | |||||
| File STref_dir | |||||
| String fasta | |||||
| String sample | |||||
| String GATKdocker | |||||
| String disk_size | |||||
| String cluster_config | |||||
| command <<< | |||||
| set -o pipefail | |||||
| set -e | |||||
| java -Dsamjdk.use_async_io_read_samtools=false -Dsamjdk.use_async_io_write_samtools=true -Dsamjdk.use_async_io_write_tribble=false -Dsamjdk.compression_level=2 -Xmx32G -jar /gatk/gatk-package-4.1.0.0-local.jar VariantFiltration -V ${vcf_file} -O ${sample}_hc_filtered.vcf -R ${STref_dir}/${fasta} -window 35 -cluster 3 -filterName FS -filter "FS > 30.0" -filterName QD -filter "QD < 2.0" | |||||
| cat ${sample}_hc_filtered.vcf |grep "#" > ${sample}_hc_filtered.vcf.header.tmp | |||||
| cat ${sample}_hc_filtered.vcf |grep PASS > ${sample}_hc_filtered.vcf.tmp | |||||
| cat ${sample}_hc_filtered.vcf.header.tmp ${sample}_hc_filtered.vcf.tmp > ${sample}_hc_PASS.vcf | |||||
| >>> | |||||
| runtime { | |||||
| docker:GATKdocker | |||||
| cluster:cluster_config | |||||
| systemDisk: "cloud_ssd 40" | |||||
| dataDisk: "cloud_ssd " + disk_size + " /cromwell_root/" | |||||
| } | |||||
| output { | |||||
| File raw_vcf = "${sample}_hc_filtered.vcf" | |||||
| File pass_vcf = "${sample}_hc_PASS.vcf" | |||||
| } | |||||
| } | |||||
+ 56
- 0
tasks/Metrics.wdl
查看文件
| task Metrics { | |||||
| File STref_dir | |||||
| String SENTIEON_INSTALL_DIR | |||||
| String sample | |||||
| String STdocker | |||||
| String cluster_config | |||||
| String fasta | |||||
| File sorted_bam | |||||
| File sorted_bam_index | |||||
| String disk_size | |||||
| command <<< | |||||
| set -o pipefail | |||||
| set -e | |||||
| export SENTIEON_LICENSE=192.168.0.55:8990 | |||||
| nt=$(nproc) | |||||
| ${SENTIEON_INSTALL_DIR}/bin/sentieon driver -r ${STref_dir}/${fasta} -t $nt -i ${sorted_bam} --algo MeanQualityByCycle ${sample}_mq_metrics.txt --algo QualDistribution ${sample}_qd_metrics.txt --algo GCBias --summary ${sample}_gc_summary.txt ${sample}_gc_metrics.txt --algo AlignmentStat ${sample}_aln_metrics.txt --algo InsertSizeMetricAlgo ${sample}_is_metrics.txt --algo CoverageMetrics --omit_base_output ${sample}_coverage_metrics | |||||
| ${SENTIEON_INSTALL_DIR}/bin/sentieon plot metrics -o ${sample}_metrics_report.pdf gc=${sample}_gc_metrics.txt qd=${sample}_qd_metrics.txt mq=${sample}_mq_metrics.txt isize=${sample}_is_metrics.txt | |||||
| >>> | |||||
| runtime { | |||||
| docker:STdocker | |||||
| cluster: cluster_config | |||||
| systemDisk: "cloud_ssd 40" | |||||
| dataDisk: "cloud_ssd " + disk_size + " /cromwell_root/" | |||||
| } | |||||
| output { | |||||
| File qd_metrics = "${sample}_qd_metrics.txt" | |||||
| File qd_metrics_pdf = "${sample}_qd_metrics.pdf" | |||||
| File mq_metrics = "${sample}_mq_metrics.txt" | |||||
| File mq_metrics_pdf = "${sample}_mq_metrics.pdf" | |||||
| File is_metrics = "${sample}_is_metrics.txt" | |||||
| File is_metrics_pdf = "${sample}_is_metrics.pdf" | |||||
| File gc_summary = "${sample}_gc_summary.txt" | |||||
| File gc_metrics = "${sample}_gc_metrics.txt" | |||||
| File gc_metrics_pdf = "${sample}_gc_metrics.pdf" | |||||
| File aln_metrics = "${sample}_aln_metrics.txt" | |||||
| File coverage_metrics_sample_summary = "${sample}_coverage_metrics.sample_summary" | |||||
| File coverage_metrics_sample_statistics = "${sample}_coverage_metrics.sample_statistics" | |||||
| File coverage_metrics_sample_interval_statistics = "${sample}_coverage_metrics.sample_interval_statistics" | |||||
| File coverage_metrics_sample_cumulative_coverage_proportions = "${sample}_coverage_metrics.sample_cumulative_coverage_proportions" | |||||
| File coverage_metrics_sample_cumulative_coverage_counts = "${sample}_coverage_metrics.sample_cumulative_coverage_counts" | |||||
| } | |||||
| } | |||||
+ 29
- 0
tasks/SamToBam.wdl
查看文件
| task SamToBam { | |||||
| File aligned_sam | |||||
| String sample | |||||
| String PIdocker | |||||
| String cluster_config | |||||
| String disk_size | |||||
| String id | |||||
| String library | |||||
| String platform | |||||
| String machine | |||||
| command <<< | |||||
| set -o pipefail | |||||
| set -e | |||||
| java -jar /usr/bin/picard/picard.jar AddOrReplaceReadGroups I=${aligned_sam} O=${sample}.bam SO=coordinate RGID=${id} RGLB=${library} RGPL=${platform} RGPU=${machine} RGSM=${sample} | |||||
| >>> | |||||
| runtime { | |||||
| docker:PIdocker | |||||
| cluster: cluster_config | |||||
| systemDisk: "cloud_ssd 40" | |||||
| dataDisk: "cloud_ssd " + disk_size + " /cromwell_root/" | |||||
| } | |||||
| output { | |||||
| File sorted_bam = "${sample}.bam" | |||||
| } | |||||
| } |
+ 40
- 0
tasks/SplitReads.wdl
查看文件
| task SplitReads { | |||||
| String SENTIEON_INSTALL_DIR | |||||
| String sample | |||||
| File STref_dir | |||||
| File fasta | |||||
| File Dedup_bam | |||||
| File Dedup_bam_index | |||||
| String STdocker | |||||
| String cluster_config | |||||
| String disk_size | |||||
| command <<< | |||||
| set -o pipefail | |||||
| set -e | |||||
| export SENTIEON_LICENSE=192.168.0.55:8990 | |||||
| nt=$(nproc) | |||||
| ${SENTIEON_INSTALL_DIR}/bin/sentieon driver -t $nt -r ${STref_dir}/${fasta} -i ${Dedup_bam} --algo RNASplitReadsAtJunction --reassign_mapq 255:60 ${sample}.split.bam | |||||
| >>> | |||||
| runtime { | |||||
| docker:STdocker | |||||
| cluster: cluster_config | |||||
| systemDisk: "cloud_ssd 40" | |||||
| dataDisk: "cloud_ssd " + disk_size + " /cromwell_root/" | |||||
| } | |||||
| output { | |||||
| File Split_bam = "${sample}.split.bam" | |||||
| File Split_bam_index = "${sample}.split.bam.bai" | |||||
| } | |||||
| } | |||||
+ 37
- 0
tasks/deduped_Metrics.wdl
查看文件
| task deduped_Metrics { | |||||
| File STref_dir | |||||
| String SENTIEON_INSTALL_DIR | |||||
| String sample | |||||
| String fasta | |||||
| File Dedup_bam | |||||
| File Dedup_bam_index | |||||
| String STdocker | |||||
| String cluster_config | |||||
| String disk_size | |||||
| command <<< | |||||
| set -o pipefail | |||||
| set -e | |||||
| export SENTIEON_LICENSE=192.168.0.55:8990 | |||||
| nt=$(nproc) | |||||
| ${SENTIEON_INSTALL_DIR}/bin/sentieon driver -r ${STref_dir}/${fasta} -t $nt -i ${Dedup_bam} --algo CoverageMetrics --omit_base_output ${sample}_deduped_coverage_metrics --algo MeanQualityByCycle ${sample}_deduped_mq_metrics.txt --algo QualDistribution ${sample}_deduped_qd_metrics.txt --algo GCBias --summary ${sample}_deduped_gc_summary.txt ${sample}_deduped_gc_metrics.txt --algo AlignmentStat ${sample}_deduped_aln_metrics.txt --algo InsertSizeMetricAlgo ${sample}_deduped_is_metrics.txt | |||||
| >>> | |||||
| runtime { | |||||
| docker:STdocker | |||||
| cluster: cluster_config | |||||
| systemDisk: "cloud_ssd 40" | |||||
| dataDisk: "cloud_ssd " + disk_size + " /cromwell_root/" | |||||
| } | |||||
| output { | |||||
| File deduped_coverage_metrics_sample_summary = "${sample}_deduped_coverage_metrics.sample_summary" | |||||
| File deduped_coverage_metrics_sample_statistics = "${sample}_deduped_coverage_metrics.sample_statistics" | |||||
| File deduped_coverage_metrics_sample_interval_statistics = "${sample}_deduped_coverage_metrics.sample_interval_statistics" | |||||
| File deduped_coverage_metrics_sample_cumulative_coverage_proportions = "${sample}_deduped_coverage_metrics.sample_cumulative_coverage_proportions" | |||||
| File deduped_coverage_metrics_sample_cumulative_coverage_counts = "${sample}_deduped_coverage_metrics.sample_cumulative_coverage_counts" | |||||
| } | |||||
| } |
+ 23
- 0
tasks/indexBam.wdl
查看文件
| task indexBam { | |||||
| File sorted_bam | |||||
| String sample | |||||
| String SAMdocker | |||||
| String cluster_config | |||||
| String disk_size | |||||
| command <<< | |||||
| set -o pipefail | |||||
| set -e | |||||
| samtools index ${sorted_bam} | |||||
| >>> | |||||
| runtime { | |||||
| docker:SAMdocker | |||||
| cluster: cluster_config | |||||
| systemDisk: "cloud_ssd 40" | |||||
| dataDisk: "cloud_ssd " + disk_size + " /cromwell_root/" | |||||
| } | |||||
| output { | |||||
| File sorted_bam_index = "${sample}_Aligned.sortedByCoord.out.bam.bai" | |||||
| } | |||||
| } |
+ 36
- 0
tasks/mapping.wdl
查看文件
| task mapping { | |||||
| File SAref_dir | |||||
| File STref_dir | |||||
| File fasta | |||||
| File fastq_1 | |||||
| File fastq_2 | |||||
| String sample | |||||
| String SAdocker | |||||
| String cluster_config | |||||
| String disk_size | |||||
| command <<< | |||||
| set -o pipefail | |||||
| set -e | |||||
| STAR --genomeDir ${SAref_dir} --readFilesIn ${fastq_1} ${fastq_2} --runThreadN 20 --outFileNamePrefix OnePass_ | |||||
| genomeDir=./twoPass | |||||
| STAR --runMode genomeGenerate --genomeDir $genomeDir --genomeFastaFiles ${STref_dir}/${fasta} --sjdbFileChrStartEnd OnePass_SJ.out.tab --sjdbOverhang 75 --runThreadN 20 | |||||
| STAR --genomeDir $genomeDir --readFilesIn ${fastq_1} ${fastq_2} --runThreadN 20 --outFileNamePrefix ${sample}_ | |||||
| >>> | |||||
| runtime { | |||||
| docker:SAdocker | |||||
| cluster: cluster_config | |||||
| systemDisk: "cloud_ssd 40" | |||||
| dataDisk: "cloud_ssd " + disk_size + " /cromwell_root/" | |||||
| } | |||||
| output { | |||||
| File aligned_sam = "${sample}_Aligned.out.sam" | |||||
| } | |||||
| } |
+ 170
- 0
workflow.wdl
查看文件
| import "./tasks/mapping.wdl" as mapping | |||||
| import "./tasks/SamToBam.wdl" as SamToBam | |||||
| import "./tasks/indexBam.wdl" as indexBam | |||||
| import "./tasks/Metrics.wdl" as Metrics | |||||
| import "./tasks/Dedup.wdl" as Dedup | |||||
| import "./tasks/deduped_Metrics.wdl" as deduped_Metrics | |||||
| import "./tasks/SplitReads.wdl" as SplitReads | |||||
| import "./tasks/BQSR.wdl" as BQSR | |||||
| import "./tasks/Haplotyper.wdl" as Haplotyper | |||||
| import "./tasks/Hardfiltration.wdl" as Hardfiltration | |||||
| workflow {{ project_name }} { | |||||
| File fastq_1 | |||||
| File fastq_2 | |||||
| File SAref_dir | |||||
| File STref_dir | |||||
| File dbsnp_dir | |||||
| File dbsnp | |||||
| File dbmills_dir | |||||
| File db_mills | |||||
| String SENTIEON_INSTALL_DIR | |||||
| String sample | |||||
| String STdocker | |||||
| String SAMdocker | |||||
| String SAdocker | |||||
| String PIdocker | |||||
| String GATKdocker | |||||
| String fasta | |||||
| String disk_size | |||||
| String cluster_config | |||||
| String id | |||||
| String library | |||||
| String platform | |||||
| String machine | |||||
| call mapping.mapping as mapping { | |||||
| input: | |||||
| SAref_dir=SAref_dir, | |||||
| STref_dir=STref_dir, | |||||
| sample=sample, | |||||
| fasta=fasta, | |||||
| fastq_1=fastq_1, | |||||
| fastq_2=fastq_2, | |||||
| SAdocker=SAdocker, | |||||
| disk_size=disk_size, | |||||
| cluster_config=cluster_config | |||||
| } | |||||
| call SamToBam.SamToBam as SamToBam { | |||||
| input: | |||||
| aligned_sam=mapping.aligned_sam, | |||||
| sample=sample, | |||||
| id=id, | |||||
| library=library, | |||||
| platform=platform, | |||||
| machine=machine, | |||||
| PIdocker=PIdocker, | |||||
| disk_size=disk_size, | |||||
| cluster_config=cluster_config | |||||
| } | |||||
| call indexBam.indexBam as indexBam { | |||||
| input: | |||||
| sample=sample, | |||||
| sorted_bam=SamToBam.sorted_bam, | |||||
| SAMdocker=SAMdocker, | |||||
| disk_size=disk_size, | |||||
| cluster_config=cluster_config | |||||
| } | |||||
| call Metrics.Metrics as Metrics { | |||||
| input: | |||||
| SENTIEON_INSTALL_DIR=SENTIEON_INSTALL_DIR, | |||||
| fasta=fasta, | |||||
| STref_dir=STref_dir, | |||||
| sorted_bam=SamToBam.sorted_bam, | |||||
| sorted_bam_index=indexBam.sorted_bam_index, | |||||
| sample=sample, | |||||
| STdocker=STdocker, | |||||
| disk_size=disk_size, | |||||
| cluster_config=cluster_config | |||||
| } | |||||
| call Dedup.Dedup as Dedup { | |||||
| input: | |||||
| SENTIEON_INSTALL_DIR=SENTIEON_INSTALL_DIR, | |||||
| sorted_bam=SamToBam.sorted_bam, | |||||
| sorted_bam_index=indexBam.sorted_bam_index, | |||||
| sample=sample, | |||||
| STdocker=STdocker, | |||||
| disk_size=disk_size, | |||||
| cluster_config=cluster_config | |||||
| } | |||||
| call deduped_Metrics.deduped_Metrics as deduped_Metrics { | |||||
| input: | |||||
| SENTIEON_INSTALL_DIR=SENTIEON_INSTALL_DIR, | |||||
| fasta=fasta, | |||||
| STref_dir=STref_dir, | |||||
| Dedup_bam=Dedup.Dedup_bam, | |||||
| Dedup_bam_index=Dedup.Dedup_bam_index, | |||||
| sample=sample, | |||||
| STdocker=STdocker, | |||||
| disk_size=disk_size, | |||||
| cluster_config=cluster_config | |||||
| } | |||||
| call SplitReads.SplitReads as SplitReads { | |||||
| input: | |||||
| SENTIEON_INSTALL_DIR=SENTIEON_INSTALL_DIR, | |||||
| fasta=fasta, | |||||
| STref_dir=STref_dir, | |||||
| Dedup_bam=Dedup.Dedup_bam, | |||||
| Dedup_bam_index=Dedup.Dedup_bam_index, | |||||
| sample=sample, | |||||
| STdocker=STdocker, | |||||
| disk_size=disk_size, | |||||
| cluster_config=cluster_config | |||||
| } | |||||
| call BQSR.BQSR as BQSR { | |||||
| input: | |||||
| SENTIEON_INSTALL_DIR=SENTIEON_INSTALL_DIR, | |||||
| fasta=fasta, | |||||
| dbsnp_dir=dbsnp_dir, | |||||
| dbsnp=dbsnp, | |||||
| dbmills_dir=dbmills_dir, | |||||
| db_mills=db_mills, | |||||
| STref_dir=STref_dir, | |||||
| Split_bam=SplitReads.Split_bam, | |||||
| Split_bam_index=SplitReads.Split_bam_index, | |||||
| sample=sample, | |||||
| STdocker=STdocker, | |||||
| disk_size=disk_size, | |||||
| cluster_config=cluster_config | |||||
| } | |||||
| call Haplotyper.Haplotyper as Haplotyper { | |||||
| input: | |||||
| SENTIEON_INSTALL_DIR=SENTIEON_INSTALL_DIR, | |||||
| fasta=fasta, | |||||
| STref_dir=STref_dir, | |||||
| recaled_bam=BQSR.recaled_bam, | |||||
| recaled_bam_index=BQSR.recaled_bam_index, | |||||
| dbsnp_dir=dbsnp_dir, | |||||
| dbsnp=dbsnp, | |||||
| sample=sample, | |||||
| STdocker=STdocker, | |||||
| disk_size=disk_size, | |||||
| cluster_config=cluster_config | |||||
| } | |||||
| call Hardfiltration.Hardfiltration as Hardfiltration { | |||||
| input: | |||||
| fasta=fasta, | |||||
| STref_dir=STref_dir, | |||||
| vcf_file=Haplotyper.vcf, | |||||
| vcf_index=Haplotyper.vcf_idx, | |||||
| sample=sample, | |||||
| GATKdocker=GATKdocker, | |||||
| disk_size=disk_size, | |||||
| cluster_config=cluster_config | |||||
| } | |||||
| } | |||||
正在加载...